[月別過去ログ] 2005年01月
« 2004年12月 | 最新のページに戻る | 2005年02月 »2005年01月31日
■ 手作りパソコンの価格が納得できません
[教えて!goo] 手作りパソコンの価格が納得できません。
via ARTIFACT ―人工事実―
いやー、ぜったいネタでしょ。しかしこのフラグの立たなさっぷり、明らかにムダな努力。自作男のその気持ち、よくわかる。すげ―泣ける。そんなとんちんかんな努力をしなかった、と言える者は石もてこの自作男を打て。私は打てないっすよ。なんか胸が疼いてきた(妄想と回想が進みすぎ)。
しかもそのたった2週間後にシステムおかしくなってるし:[教えて!goo] アイコンが動かない、データ移動もできない。
・・って最近「雑記」ばっかりです。
■ 敬称
ネット上での敬称、私自身はいくつか決めているつもりのことがあるので整理してみたらこうなりました。(2/3加筆)
んで、実生活での呼び方は以下の通り。
- 自分のmentorには「先生」をつける。
- それ以外は全部「さん」付けにしたい。
というわけで言いたいことは要するに、私自身のこともけっして「先生」付けせずに呼んでいただきたい、ということです。
2005年01月29日
■ movは開かない
なんでオンラインジャーナルの動画ファイルはmovだけしか掲載しないんすかね。WindowsユーザーはQuickTimeをインストールしないといけないではないですか(TMPGEnc + QTReader.vfpもQuickTimeをインストールしないと使えないですよね)。かつてQuickTimeをアンインストールしようとしたときはシステムがおかしくなるかもしれないがそれでもアンインストールするか、とか脅しをかけてきたんで、今のシステムには入れてないんです。いや、Windows media playerだって同罪です。だけど、せめてmpegとmovと両方を掲載するようにしとけばいいのに。そういえばLinuxの人にはなにが最適なんだろ。
2005年01月28日
■ 生理学会に向けてダッシュしてます。
今日は木下先生による講義「回転する分子モーターとATP合成」があるのでラボのサイトへ行ってryasudaさんの論文やレビューとか含めていくつかダウンロードしたんで、読んでから聞きに行こうと思ったのだけれど、けっきょく聞きに行けず。ほかにネットで手に入る資料にはNetScience Interview Mail(1998)があります。
2005年01月27日
■ JNP February 2005
- "Physiological Characterization of Synaptic Inputs to Inhibitory Burst Neurons From the Rostral and Caudal Superior Colliculus" J Neurophysiol 93: 697-712, 2005. Y. Sugiuchi, Y. Izawa, M. Takahashi, J. Na, and Y. Shinoda [EndNote format]
- "So Much to See, So Little Time: How the Superior Colliculus (SC) Suppresses Unwanted Saccades." [EndNote format] 上記論文へのコメンタリ
- "Internal Models and Contextual Cues: Encoding Serial Order and Direction of Movement." [EndNote format] Reza Shadmehr
- "Neuronal Activity in Macaque SEF and ACC During Performance of Tasks Involving Conflict." Kae Nakamura, Matthew R. Roesch, and Carl R. Olson [EndNote format]
- "Spatial Overlap of ON and OFF Subregions and Its Relation to Response Modulation Ratio in Macaque Primary Visual Cortex." Mario L. Mata, and Dario L. Ringach [EndNote format]
- "Integration of Target and Effector Information in Human Posterior Parietal Cortex for the Planning of Action." W. Pieter Medendorp, Herbert C. Goltz, J. Douglas Crawford, and Tutis Vilis [EndNote format]
- "A Point Process Framework for Relating Neural Spiking Activity to Spiking History, Neural Ensemble, and Extrinsic Covariate Effects." Wilson Truccolo, Uri T. Eden, Matthew R. Fellows, John P. Donoghue, and Emery N. Brown [EndNote format]
- "Task-Specific Sensorimotor Adaptation to Reversing Prisms." Jonathan J. Marotta, Gerald P. Keith, and J. Douglas Crawford [EndNote format]
- / ツイートする
- / 投稿日: 2005年01月27日
- / カテゴリー: [Paper archive]
- / Edit(管理者用)
2005年01月26日
■ 論文いろいろ
PNAS 1/25
- "Redefining implicit and explicit memory: The functional neuroanatomy of priming, remembering, and control of retrieval" PNAS 102: 1257-1262; Björn H. Schott, Richard N. Henson, Alan Richardson-Klavehn, Christine Becker, Volker Thoma, Hans-Jochen Heinze, and Emrah Düzel [EndNote format]
- "The Müller-Lyer illusion explained by the statistics of image-source relationships" PNAS 102: 1234-1239; Catherine Q. Howe, and Dale Purves [EndNote format] Müller-Lyer illusionってのはあれです、>--<のほうが<-->よりも長く見える、というやつ。この表記では正確でないけれど。
- "Natural-scene geometry predicts the perception of angles and line orientation" PNAS 102: 1228-1233; Catherine Q. Howe and Dale Purves [EndNote format]
- "Anticipating the three-dimensional consequences of eye movements" PNAS 102: 1246-1251; Mark Wexler [EndNote format]
Neuron 1/20
- "Theta Burst Stimulation of the Human Motor Cortex." Neuron, Volume 45, Issue 2, 20 January 2005, Pages 201-206 Ying-Zu Huang, Mark J. Edwards, Elisabeth Rounis, Kailash P. Bhatia and John C. Rothwell
- "Toward Establishing a Therapeutic Window for rTMS by Theta Burst Stimulation." Neuron, Volume 45, Issue 2, 20 January 2005, Pages 181-183 Walter Paulus
- "Expansion of Direction Space around the Cardinal Axes Revealed by Smooth Pursuit Eye Movements." Neuron, Volume 45, Issue 2, 20 January 2005, Pages 315-323 Anton E. Krukowski and Leland S. Stone
- / ツイートする
- / 投稿日: 2005年01月26日
- / カテゴリー: [Paper archive]
- / Edit(管理者用)
2005年01月25日
■ 「ログインしてください。」
より良いCMSを作る
via YAMDAS現更新履歴1/24
これにコメントを付けられるほどにCMSの事を知っているわけではないけれど、"Users of a public Web site should never, never, be presented with a way to log in to the CMS"というのにはあー、やっぱり、と思ってしまうのです。
あの「登録してログインしてください」ってのがものすごい心理的に障壁なんですよね。半年ROMってから書き込む、というような形でだんだん参加したいのにそれがしにくくなるわけです。けっきょくは気心知れた人のあいだで使うグループウェアとしての側面のほうが強いのだと理解しております。
似たようなことはブログでもあって、Movable typeでもTypeKeyというのを使ってサインインしないとコメントを書き込みできないようにする機能があるし、MSNブログでも「コメントを投稿するには、Microsoft .NET Passport を使用してこの Web サイトにサインインする必要があります。」というのがあります。これらは「半年ROMってから」いざ書き込むときにはじめて出てくるのでより心理的障壁は低いわけですが、それでも気になります。Six Apart自体がコメントスパム対策のひとつとしてTypeKey使用を推奨しているわけですが、ほかのやり方で対処したほうがよいかと考えています。追記:あ、べつにこのサイトに書き込む前に半年ROMれ、なんてぜったい言いませんので。
2005年01月24日
■ JNS 1/19 Out-of-Body Experience
"Linking Out-of-Body Experience and Self Processing to Mental Own-Body Imagery at the Temporoparietal Junction." Olaf Blanke, Christine Mohr, Christoph M. Michel, Alvaro Pascual-Leone, Peter Brugger, Margitta Seeck, Theodor Landis, and Gregor Thut [EndNote format]
Olaf Blankeはこれまでにも
Brain '04 "Out-of-body experience and autoscopy of neurological origin." Brain 127: 243-258 Olaf Blanke, Theodor Landis, Laurent Spinelli, and Margitta Seeck [EndNote format]
Nature '02 (brief communications) "Stimulating illusory own-body perceptions." Nature 419, 269 - 270 (19 September 2002); OLAF BLANKE, STPHANIE ORTIGUE, THEODOR LANDIS and MARGITTA SEECK [ris format]
などを立て続けに出して、'Out-of-body' experiences (OBEs)に関する仕事を続けています。
cogniさんのところの1/20にも記載がありますように、temporoparietal junction (TPJ)のはたす役割、という意味でも重要な知見です。うちのサイトのOptic ataxiaに関するスレッドやSpatial hemineglectに関するスレッドともおおいに関係があります。
- / ツイートする
- / 投稿日: 2005年01月24日
- / カテゴリー: [Papers_unclassified]
- / Edit(管理者用)
2005年01月22日
■ Nature AOP 1/19
"Functional imaging with cellular resolution reveals precise micro-architecture in visual cortex." KENICHI OHKI, SOOYOUNG CHUNG, YEANG H. CH'NG, PRAKASH KARA and R. CLAY REID [ris format]
via ご隠居のにゅーろん徒然草 1/22
20041105でのSFNレポートで言及した大木さん@CLAY REID研のin vivo two-photonでのfunctional imagingの仕事がNatureのAOPに掲載されてます。おめでとうございます! Figure 1-3はSFNでも見たもの、Figure 5はあった気もするけど覚えてません(でも当然必要なもの)。Figure 4を見るといかに劇的にpreferred directionが変化するかがよくわかります。
この技法をもとにいろんな知見が出てくると思いますが(他の属性のマップはどんなか、anatomyとの対応はどんなか、whole-cellとの組み合わせでもっといろんな操作をする、behaving animalでの応用、ときりがない!)、それは続報待ちということでしょう。
それから、2005年以内出版を目指して追っかけてくるラボがどのくらい出てくるか、それとも独走するのか、さまざまなラボが参入するような標準的な技法となるのか、これはもう目が離せません。
- / ツイートする
- / 投稿日: 2005年01月22日
- / カテゴリー: [Two-photon in vivo imaging]
- / Edit(管理者用)
2005年01月21日
■ XHTML1.0 Transitionalでvalidにしてみました
このサイトをWeb標準に準拠させるということで、インデックスページに関してだけvalidatorでXHTML1.0 Transitionalとして合格するようにしてみました。
まずAnother HTML-lint gatewayにかけてみると-1点とか出ます。教えに従って、</p>の入れ忘れや空要素の閉じ忘れ(<img />とか)を直します。あと、movable typeの編集画面で「改行を変換する」にしておくと、<p></p>の中に<blockquote>や<ul>が入ったりといった、ブロック要素の混乱が起こるのでこれを整理します。さらに<A HREF="">を<a href="">に直すとかしょうもないことをいろいろやって50点までたどり着きました。
やっかいなのはcgiに送るurlの中にしばしば&が入っている、というやつで、AdminLinks.plがcgiに送るurlの&を&amp;に置換するためにAdminLinks.plのソース自体を直して再構築しました。っつーか、これって"Edit Entry"が丸見えってことですか(気付いてなかった…実害ないけど)。それから、PLoS biologyのfulltextのurlには&が入っているのでこれも&amp;に置換しないといけない(こんなこと毎日やってられないな)。このへんをやってやっと77点まできました。
そこで、W3Cのvalidatorにかけてみると、validになりました。
というわけでいつまでもつかわからないけど、validアイコンを貼っておきます。
■ JNS
JNS 1/12
- "Adaptation to Visuomotor Transformations: Consolidation, Interference, and Forgetting" J. Neurosci. 25: 473-478; John W. Krakauer, Claude Ghez, and M. Felice Ghilardi [EndNote format]
- "Modality-Specific Cognitive Function of Medial and Lateral Human Brodmann Area 6." J. Neurosci. 25: 496-501; Satoshi Tanaka, Manabu Honda, and Norihiro Sadato [EndNote format] 定藤先生のところから。
- "Distinct Properties of Stimulus-Evoked Bursts in the Lateral Geniculate Nucleus." J. Neurosci. 25: 514-523; Henry J. Alitto, Theodore G. Weyand, and W. Martin Usrey [EndNote format]
- "Prefrontal Serotonin Depletion Affects Reversal Learning But Not Attentional Set Shifting." J. Neurosci. 25: 532-538; H. F. Clarke, S. C. Walker, H. S. Crofts, J. W. Dalley, T. W. Robbins, and A. C. Roberts [EndNote format] 5,7-dihydroxytryptamineによるセロトニンのdepletion
JNS 1/19
- "Correlation between Speed Perception and Neural Activity in the Middle Temporal Visual Area." J. Neurosci. 25: 711-722; Jing Liu, and William T. Newsome [EndNote format] これまでのdirectionに関するperceptual decisionではなくてspeed perceptionに関して同様にMTにmicrostimulationして反応をバイアスさせたもの。連続量なのでどのように扱うかと思ったら、三種類のチューニングを持ったニューロン集団(低速、中速、高速)によってjudgeしている、という話にしているらしい(図4を見るかぎり)。
- / ツイートする
- / 投稿日: 2005年01月21日
- / カテゴリー: [Paper archive]
- / Edit(管理者用)
2005年01月20日
■ Scienceのwebサイト
のfulltextのページにadvertizement(annual reviewsのやつ)が入ったことで激しくレイアウトが狂ってます。なんでこのまま放置してるんだろ。しかもfirefox1.0だけでなくinternet explorer 6でもおかしいんですけど。たとえば昔の論文、適当にhttp://www.sciencemag.org/cgi/content/full/275/5306/1593とかでみると、バックが白いところと灰色のところがある(Fig.2の後ろで必ずこうなるらしい)。
■ Nature Neuroscience AOP
"A representation of the hazard rate of elapsed time in macaque area LIP." Published online: 16 January 2005; Peter Janssen and Michael N Shadlen [ris format]
まえのNeuron '03(Leon and Shadlen)と併せてこのへん採りあげる意義はあるでしょうな。ちなみに"Neural correlates of time perception"に関するメモは20040914のエントリにあります。
- / ツイートする
- / 投稿日: 2005年01月20日
- / カテゴリー: [Paper archive]
- / Edit(管理者用)
2005年01月19日
■ PNAS 1/18
- "Inaugural Article: Biography of William T. Newsome." PNAS 102: 521-523; Emma Hitt [EndNote format] Newsomeの仕事について書かれています。Newsome自身は2000年からすでにNASのメンバーになっているものの、自分の仕事をPNASにcontributeするのははじめてなのでこういう記事がaccompanyしたもよう。ちなみに"by William T. Newsome" site:www.pnas.orgでググってみたところ、edited byやcommunicated byはすでに3つくらいの論文でやってます。
- "Microstimulation of the superior colliculus focuses attention without moving the eyes." PNAS 102: 524-529; James R. Müller, Marios G. Philiastides, and William T. Newsome [EndNote format] んでこれがNewsomeのInaugural Article。上丘の刺激でサッケードを誘発しない強度のところでattentionをバイアスさせる、というもの。自身のScience '99("Separate Signals for Target Selection and Movement Specification in the Superior Colliculus." Horwitz, Gregory D., Newsome, William T [EndNote format])やKrauzlisのNeuron '04 "Manipulating intent: evidence for a causal role of the superior colliculus in target selection." Christopher D. Carello and Richard J. Krauzlis Neuron, Volume 43, Issue 4, 19 August 2004, Pages 575-583.と比べてどんな感じか、というあたりが焦点となるでしょうか。
- "A cortico-cortical mechanism mediating object-driven grasp in humans." PNAS 102: 898-903; L. Cattaneo, M. Voss, T. Brochier, G. Prabhu, D. M. Wolpert, and R. N. Lemon [EndNote format]
- "The neocortical microcircuit as a tabula rasa." PNAS 102: 880-885; Nir Kalisman, Gilad Silberberg, and Henry Markram [EndNote format] ラブララサときましたよ、Henry Markram。Layer 5 neuronのaxonal arborやdendritic arborの広がりはランダムにバイアスなしに周りのニューロンに延びていて、それがじっさいにどのようにfunctionalにカップルしているかは周りのニューロンと接する場所にsynaptic boutonがあるかどうかによるのだと。うーむ、これはV1のconnectivityやbarrelでのconnectivityとかとの知見とどう整合性が取れるかでしょうな。
- "Visual extrapolation of contour geometry." PNAS 102: 939-944; Manish Singh, and Jacqueline M. Fulvio [EndNote format]
- / ツイートする
- / 投稿日: 2005年01月19日
- / カテゴリー: [Paper archive]
- / Edit(管理者用)
2005年01月18日
■ 昨日と今日は研究会
だったのですが、時間がなかったので二つだけ聞きに行って質問してきました。詳細は省略するので奥歯にものの挟まった言い方なんだけど、私が質問で聞きたかったのだけれどたんなる違和感の表明にしかならなかったものを、それぞれの質問者の方がより具体的な質問にしてだんだん解き明かしてゆく様に、ああ、そうい言えばよかったのか、とおのれの修行不足を痛感。私と同じくらいから少し上ぐらいの人たちが主な参加メンバーということもあって、もう少し参加したかったし飲みにも行きたかったのですが、残念ながら明日の準備があるのでじゅうぶん参加できませんでした。今度は発表者として参加したいと思います。
2005年01月17日
■ Dorris and Glimcher (2004)とSugrue et al(2004)(mmrlさんより)
mmrlさんが1/4コメント欄で言及していた計算をしてくださったものが届きました。許可をいただいたので以下に掲載します。mmrlさん、いつもどうもありがとうございます。ここから:
ちょっと計算してみましたのでご報告。
やったことは、matchingとmaximizing(強化学習、Optimization)で得られる解が違うのかどうかをSugrueらの離散時間型のVI-VIスケジュールで確認しました。
結論を先に言うとVI-VIの場合、
- maximizingの解はmatchingの解に一致する
- このときの各expected value for choiceは等しい
の2点です。
maximizationでは違う解が得られるのではないかと期待していたのですが、一致してかつuchidaさんが数行で計算した結果をいろいろいじくって確認しただけとなりました。また、簡単のため選択変更後遅延(change over delay, COD)はこの計算では用いていません。
7月1日に計算したように、n 回あるchoice Aを選択しなければ、そこに報酬が存在する確率は、
と表されます。ここで、は1回に報酬が降ってくる確率。
今、確率的に行動選択するとして、A を選択する確率とすると、まったくランダムに選択したとするとそのinter choice interval の分布
は
このとき、expected value for choice A, はchoice probabiltiy の関数になって、
となります。同様に
これは、を下げれば下げるほど
を上げることになります。
一方、income の方は
となりますからを下げれば0に漸近、1に近づければ
に漸近します。
maximization では、ある選択確率 のときの単位時間当たりの総報酬を最大化するわけですから、
が最大になるように、を見つければよいので微分して0に持っていけばよい。
ここで、となることに注意すると
において から
によって最適解が与えられる。
すなわち均衡解というわけです。
さて、これで得られる解が
fractional income
のどのような関数になっているかというと と
から
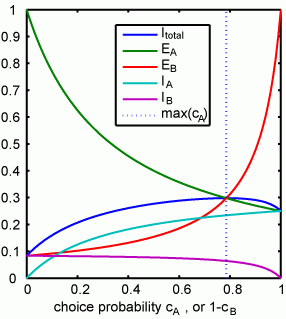
すなわちAのfractional incomeはAのchoice probability に一致する。つまりmatchingというわけです。あーつまんない計算だった。
休み2日掛けて考えたのに結局VIVIはmatching とmaximizingが一致するように巧妙に仕組まれたタスクということだけがわかりました。
これって実はBaum 1981, Heyman 1979, Staddon Motheral 1978に書かれていたいりして...、調べてから計算しよう。ああ、無駄してしまった。
7月1日に書いたことも実はmomentary maximization theory (瞬時最大化理論)と呼ばれるものと同一だったりすることを[メイザーの学習と行動」を読み返して気づいてみたり...。無駄ばっかり。
ここまでです。編集過程で間違いが混入していたらお知らせください。
いやいや、無駄ではないですよ。手を動かした人がいちばん問題を理解した人になると思いますし。
メールにも書きましたが、generalizedでないMatching lawが成り立つためにはchange over delayの導入とVI-VI concurrentであることとが必須であるという理解だったのですが、今回の計算からするとchange over delay自体はalternating choiceのstrategyを排除するためだけに必要で、そんなにエッセンシャルなものではないのかもしれませんね。
しかしここまでくるとchange over delayとtauを組み込んだときにmaximizationとmatchingとの解がどのくらいずれるかということも検証できてしまいそうですね。それについては将来の著者たちの研究を待つか、ガッツのある方の参入を期待するということで、まずはmmrlさん、ありがとうございました。
- / ツイートする
- / 投稿日: 2005年01月17日
- / カテゴリー: [価値による行動選択 (expected value)] [神経経済学 (neuroeconomics)]
- / Edit(管理者用)
# uchida
ご無沙汰しています。新しい総説、Sugrue et al (Nature Review Neurosci., 2005)、ご覧になられたことと思います。知りたかった解析(Sugrue et al., 2004 のデータをDorris et al, 2004 の方法で解析すること)が出ていますね (Figure 7)!!! 少なくともこれらふたつのニューロンはとても似た振る舞いをしていることが分かります。Population data をきっちりみたいところですが、Newsome グループがこのニューロンを出してきたということは、お互いほぼ同じようなニューロンを見ていると考えるのが自然のような気がします。驚くべき一致ですね!!! 従って、今後はどのように解釈するかということが主眼になるかとおもいますが、そのあたりは今後のGlimcher の反論も含めてじっくりみていく価値がありそうですね。
この総説で強調されている、local な解析・モデルが「メカニズム」により近いはずだから、グローバルな解析より重要だという主張は一理あります。しかし、図7は、expected value が task 中、グローバルに変動しない場合(以前私の書き込みで示したように matching task ではグローバルには expected value が変動しない)、ニューロンの発火頻度も大きく変動しないということをはっきり示しています。Newsome らに決定的に欠けているのは、Dorris et al. (2004) で行われた報酬量を変化させる実験、つまりexpected value をふる実験で、これをしない限り、localな細かな変動をあたかもすべてのように語るのは大きな間違いという気がします。大きな方手落ちです。Dorris らが示したように、報酬量を変動させたときには local fluctuation よりもずっと大きな変動を起こすことが考えられるからです。そういうことから考えると、この総説の一方的な攻撃に反して、Glimcher らが結局正しいということになるのではないかという予感がします。この総説が、著者の意図に反して大きな欠陥をさらけ出してしまうのではないか。。。
はたからみているだけでなく、自分もなにか面白いことを始めなければ。。。
2005年01月14日
■ 横スクロールバー反対、リキッドレイアウト万歳のつづき
Firefox1.0で気になることといえば、長いURL(とか数式とかとにかくスペースのない長い英数字)が折り返されずに一行に延びてしまってカラムからはみ出てしまうことなんですけど、これってブラウザのバグなんでしょうか、それともhtmlの書き方の問題なのでしょうか。Internet Explorer6.0では起こらないし(かといってIE6が正しいとは限らないけど)、Lynxでも起こらない(あたりまえか)のですが。
<pre>の中身の一行が長いときにもブラウザのウインドウ幅ではなくて一行が終わるまで横幅がひろがって、横スクロールバーが出ますよね。これはIE6でも起こることですが。
とにかくイヤなんですよ、横スクロールバーが出てくるのが。ウインドウ幅より大きい画像だったら自動的に縮小させて表示するべきだし、2カラムや3カラムでウインドウ幅からはみ出すようだったら自動的にそのカラムは左のカラムが修了したらその「下」に表示すべき(CSS外したときのように)だと思うのですよ。その意味ではCSS賛成、テーブルレイアウト大反対ですし、フレーム大反対です。
なんでそんなに横スクロールバーが嫌いかといえば、こっちはブラウザのウインドウ幅をおそらくかなり狭め(いま測ってみたけど、縦スクロールバー入れないで680pixel)にして使っていてそういう場面にぶつかることが多いからだと思うんです。そしてそれはなぜかといえば、1カラムしかなくてウインド幅をpixelなどで限定してないようなサイトのテキストを読むことをデフォルトとして考えているからなのです。そういうばあい、ウインド幅が800pixelもあったらすでに読みにくいわけです。1行の横幅が長いと読みにくいというのは、昔のIBROのNeuroscience誌が段組みなしでA4で1行丸々使われていたとき、現在の段組み2カラムと比べてどんなに読みにくかったか思いおこしていただければわかるのではないかと。
だから、対策として逆を考えることもできるわけです。リキッドレイアウトつったって1600x1200pixelの画面に全画面表示して読ませることなど誰も想定していないわけで、ブラウザ全画面表示をデフォルトにしても困らないように、ウインドウ幅をとくに指定していないhtmlに関してはブラウザの設定によって折り返す文字数かpixelを設定して勝手に折り返してもらうようにする、これでいいわけです……そんな設定いまのところないですよね。
もしくはCSSでこういう設定ができたらいいのだけれど、文字描画領域の最大幅を800pixelとか設定しておいて、ブラウザを全画面表示したときにテキストが横幅いっぱいは表示されないようになるのだけれど、ブラウザの表示領域が600pixelとかのときには途中で折り返してくれて横スクロールバーが出ないようにする。これは現状不可能ですよね?
3カラムのレイアウトのサイト(blogとかに多い)とかで、本文の部分のカラムがむちゃくちゃ狭くて携帯かなんかで読まされているかのように見えるサイトをいくつか見て、なんて変なレイアウトなんだと思っていたのだけれど、それは左右のサイドバーの幅をpixelで設定してその余りをメインコンテンツのカラム幅に充てるようになっているからだ、ということに最近気付きました。そういうところは製作者がブラウザを全画面表示にすることをデフォルトだと思っているのでしょう。
うーむ、みんなはどうしてるんだろう。どっかに統計はないもんだろうか。
2005年01月13日
■ ニコラス ハンフリー
喪失と獲得―進化心理学から見た心と体 ニコラス ハンフリー(原著は"The mind made flesh" Nicholas Humphrey) があったのではじめのほう(意識関連の部分)を少し読んでみました。意識のハードプロブレムのハードさ(コリン・マッギン流の)をいったん受け入れ、デネット流の消去主義やペンローズ-ハメロフ流の説明を行きすぎとして、進化的説明に持っていこうとするあたりの感触は悪くなさそうなので、もう少し読んでみようと思います……年度末のあれこれが無事済んだら(いやマジで)。
があったのではじめのほう(意識関連の部分)を少し読んでみました。意識のハードプロブレムのハードさ(コリン・マッギン流の)をいったん受け入れ、デネット流の消去主義やペンローズ-ハメロフ流の説明を行きすぎとして、進化的説明に持っていこうとするあたりの感触は悪くなさそうなので、もう少し読んでみようと思います……年度末のあれこれが無事済んだら(いやマジで)。
意識の進化的説明(「内なる目」も含めて)に関しては、身体化された心 フランシスコ ヴァレラ(The embodied mind" Varela)での9章「進化の道程とナチュラル・ドリフト」とつき合わせて読んでみる必要があることでしょう。
ちなみに1/6のエントリーで言及した"WHAT DO YOU BELIEVE IS TRUE EVEN THOUGH YOU CANNOT PROVE IT?"でのニコラス ハンフリーの答えはこんなかんじ。超訳、ということで勘弁。
"WHAT DO YOU BELIEVE IS TRUE EVEN THOUGH YOU CANNOT PROVE IT?"に対するニコラス ハンフリーの答え
人間の持つ「意識」とは手品の一種であって、これによってわれわれは説明のしようのない神秘があるかのように考えさせられている、そう私は信じている。誰が手品師で、なにが目的かって?手品師はnatural selectionであって、その目的はというと、人間の持つ自身への信頼と尊厳とを支えること、そうすることによって私たちが自分と他者の生命への価値を高いものとしておくことだ。
もしこの説が正しいなら、この説は私たち(科学者であろうとなかろうと)が「意識のハードプロブレム」をなんでそんなにもハードなものであると思うのか、簡単に説明してくれる。つまり、自然は意識をわざとハードなものとしたのだ。じじつ、「神秘主義的哲学者」たち(コリン・マッギン("mysterious flame")からローマ教皇まで、眼前の不可思議にひれ伏して、意識が物質的な脳から生じるということを理解するのは原理的に無理なのだと断ずる人たち)、彼らはまさに自然がそう望んだとおりに反応してみせているわけだ(衝撃と畏怖付きで)。
この説を私は証明できるかって?どうして人間がそのような経験をするのかを説明するような適応主義的な説明というものはどんなものでも証明するのは難しいのだけれど、この場合、加えて難題があるのだ。その難題は何かといえば、意識を合理的説明の届かない範囲に置くことに自然が成功したのと同じ程度に、それが自然が行ったことであるということを示す可能性そのものも自然はうまく隠しているに違いないのだ。
でもなんだって完璧ではない。抜け穴はあるかもしれない。どうやって脳で起こっている過程が意識の質的なものを持つようになったのか、をわれわれが説明するのは不可能なように見える(もしくはじじつ不可能である)いっぽうで、どうやって脳で起こっている過程がそのような質的なものを持つような印象をもつように作り上げられたかを説明することはまったく不可能なわけではないのかもしれない。(考えてみよう。わたしたちはなぜ2+2=5であるかを説明することはぜったいできないけれど、なぜあるひとが2+2=5であるというような錯覚を起こすのか、ということを説明するのはそれと比べればより容易であるだろう。)
この説を私は証明したいかって? それは難しい質問だ。もし意識が不可思議なものであるという信念が人間の希望の元であるとしたら、そのような手品の仕掛けを暴くと私たち全てが地獄に送られてしまうような危険があるのかもしれないのだから。
なお、今年の質問はニコラス ハンフリー自身が作ったものらしい。
- / ツイートする
- / 投稿日: 2005年01月13日
- / カテゴリー: [視覚的意識 (visual awareness)]
- / Edit(管理者用)
2005年01月12日
■ 月の暗い部分
月がほとんど新月状態に欠けていて、月の暗いところがうすぼんやりと見えていて、それを私は夕食を摂りに家に戻るときに自転車で坂を下りながら見た。影の中に影があるのを感じる、とはこんなことなのかもしれないと思ったり。今晩は早く寝よう。
Pooneilとはなんなのかはググればわかります。ところで私はthe tao of poohから入って遡ってMilneのpoohのファンになったclassic pooh主義者でもあります。そういえば、トイレに貼ってあるclassic poohカレンダーで今朝見た印象的なフレーズは"neiled it on its right place"。
2005年01月11日
■ 論文いろいろ
Neuron 1月号
- Direction Selectivity of Excitation and Inhibition in Simple Cells of the Cat Primary Visual Cortex, Neuron, Volume 45, Issue 1, 6 January 2005, Pages 133-145. Nicholas J. Priebe and David Ferster
- Phase Locking of Single Neuron Activity to Theta Oscillations during Working Memory in Monkey Extrastriate Visual Cortex, Neuron, Volume 45, Issue 1, 6 January 2005, Pages 147-156. Han Lee, Gregory V. Simpson, Nikos K. Logothetis and Gregor Rainer
- The Representation of Time for Motor Learning, Neuron, Volume 45, Issue 1, 6 January 2005, Pages 157-167. Javier F. Medina, Megan R. Carey and Stephen G. Lisberger
- Face Adaptation Depends on Seeing the Face, Neuron, Volume 45, Issue 1, 6 January 2005, Pages 169-175. Farshad Moradi, Christof Koch and Shinsuke Shimojo
PLoS biology 1月号
- Neuronal Encoding of Texture in the Whisker Sensory Pathway. PLoS Biol 3(1): e17 Arabzadeh E, Zorzin E, Diamond ME (2005) [EndNote format]
ところで今気付いたけれど、"download XML"というのがあって、XML形式にfulltextが格納されたものがすでにあるのですな。
- / ツイートする
- / 投稿日: 2005年01月11日
- / カテゴリー: [Paper archive]
- / Edit(管理者用)
2005年01月10日
■ Dorris and Glimcher (2004)とSugrue et al(2004)
どうも遅くなりました。頭がなかなか戻らないのでとりあえず思い出せるかぎりでレスポンスします。
まずはuchidaさん、すばらしいコメントをどうもありがとうございます。こういうサイトをやっていてよかったと思うのはまさにこういうときです。サイトなしにはなかなかお知りあいになる機会のなかった方とお知りあいになることができて、自分ひとりではできなかった議論を日本中、世界中をまたいですることができる、こういうことを積み重ねてネットワークを広げていくことができたらすばらしいと思ってます。
……global な相関(あるいは変動しないこと)と、local な相関、つまり、論文中の3つの仮説のうちのふたつ……の関係をもう少しきっちり詰めることが、この論文で示されたデータを読み解き、Sugrue et al (2004) との関係をはっきりさせる上で重要だと思います。
では、Sugrue et al論文の方はどうかというと、以前(7/5) Sugrue et al論文がglobalなmatchingとlocalなmatchingとを明示的に比較するようになっていない、ということを指摘しました。つまり、Sugrue et al論文ではLIPのactivityでglobal matchingを説明することはできなかったので、時間的にlocalなところのことしか考えていないのです。彼らはglobalにexpected value of choicesが等しいということが成り立つところでの現象を見ていないのかもしれません。
一方で、Dorris and Glimcher論文では基本的にglobalなtime scaleでナッシュ均衡が起こっていると見なしたうえで)、expected value of choicesとresponse probabilityとを分離しようとした試みである、と言えます(localなtime scaleではナッシュ均衡は成り立っていません)。
そうなると両者のあいだで見られるような矛盾はたんに見ようとしているタイムスケールの違いで解決するのかもしれません。この点でryasudaさんのご指摘にあったように、
……Nao(Uchida-san)'s statement (R_A/N_A = R_B/N_B) is not generally true for the leaky-integrator model
matching taskにおいてlocalなtime scaleではR_A/N_A = R_B/N_Bが必ずしも成り立たない、ということは大きな意味を持っていると言えます。つまりryasudaさんの予測にあるように、Sugrue et alとDorris and Glimcherのどちらにおいてもexpected value for choicesが等しいと言えるのはglobalなtime scaleでの話であって、localなtime scaleではどちらの論文でも成り立っていないのです。それで、Sugrue et alはlocalなところに話を終始させたし、Dorris and Glimcherはじゅうぶん均衡に達していないデータを使ってたのでchoice probabilityもexpected valueも変動してしまっている、というわけです。
では、Sugrue et al の model と強化学習のモデルの違いの本質はどこにあるのですか?
そもそもmatching law自体は経験的な法則であって、matching lawがどういう原理によって成立しているのかということ自体が論争になっていることについて以前触れました(6/30など)。いくつかの説の中で、Optimization (= reinforcement learning)をした結果マッチングが起こっている、という説に関しては、メイザー自身がoptimizationよりもマッチングのほうが説明力があるというデータを呈示しているらしいです(6/30)。
また、uchidaさんのご指摘に関連するところでは、Melioration theory(逐次的改良理論)という説をメイザーは押しています。Melioration theoryとは、二つのchoiceのあいだで選択数/強化が等しくなるように選択をした結果、マッチングが成り立つ、というものです(手元に「メイザーの学習と行動」がないのでhttp://www.montana.edu/wwwpy/Faculty/Lynch/MazurChap14.htmを参考に)。まさにこのリンクにも書いてありますが、逆数を取ればpayoff rate (= reinforcement/no of choices = expected value for choices)で、uchidaさんが見出したものと同じものとなります。つまり、Melioration theoryが正しいとすると、二つの選択肢のexpected valueが等しくなるように選択率を調整することによってその結果、マッチングが成り立つ、ということになります。これは二つの選択肢に関してindifferentになるように選択する、というまさにゲーム理論的な行動の現れと取ることができます。じっさい、以前リンクした"高橋雅治(1997) 選択行動の研究における最近の展開:比較意思決定研究にむけて"でも最後のほうに選択理論とプロスペクト理論とを関連付ける(将来的に融合される)という展望について語られています。
というあたりまで見渡してみると、uchidaさんのご指摘はまさにいまホットな話題である部分に直接関わることであり、今後の意思決定の研究がどういう道具立てで行くべきか、つまりゲーム理論/強化学習/選択理論をどう統一的なフレームワークで扱うか、ということに関する本質的な議論なのではないかと思います。
- / ツイートする
- / 投稿日: 2005年01月10日
- / カテゴリー: [価値による行動選択 (expected value)] [神経経済学 (neuroeconomics)]
- / Edit(管理者用)
2005年01月07日
■ Cerebral Cortex 2月号
- "Impaired Filtering of Distracter Stimuli by TE Neurons following V4 and TEO Lesions in Macaques" Cerebral Cortex Advance Access published on February 1, 2005 Elizabeth A. Buffalo , Giuseppe Bertini , Leslie G. Ungerleider , and Robert Desimone [EndNote format]
- "Time Modulated Prefrontal and Parietal Activity during the Maintenance of Integrated Information as Revealed by Magnetoencephalography" Cerebral Cortex Advance Access published on February 1, 2005 Pablo Campo, Fernando Maestú, Tomás Ortiz, Almudena Capilla, Marta Santiuste, Alberto Fernández, and Carlos Amo [EndNote format]
- "Axons in Cat Visual Cortex are Topologically Self-similar." Cereb. Cortex 15: 152-165. Tom Binzegger , Rodney J. Douglas , and Kevan A.C. Martin [EndNote format]
- "Right Temporoparietal Cortex Activation during Visuo-proprioceptive Conflict." Cereb. Cortex 15: 166-169 Daniela Balslev, Finn Å. Nielsen, Olaf B. Paulson, and Ian Law [EndNote format]
- / ツイートする
- / 投稿日: 2005年01月07日
- / カテゴリー: [Paper archive]
- / Edit(管理者用)
2005年01月06日
■ 「証明はできないけれどこれは本当だ、と信じていることってありますか?」
via http://d.hatena.ne.jp/umedamochio/20050105/p4 The Edge Annual Question—2005
"WHAT DO YOU BELIEVE IS TRUE EVEN THOUGH YOU CANNOT PROVE IT?"
Great minds can sometimes guess the truth before they have either the evidence or arguments for it (Diderot called it having the "esprit de divination"). What do you believe is true even though you cannot prove it?
意識と心の哲学関連あたり(Nicholas Humphrey, Daniel C. Dennett, William Calvin, Steven Pinker, Susan Blackmore, Piet Hut, Thomas Metzinger, Ned Block and Tor Nørretranders)がいちばん面白そう。
NeuroscientistはJoseph LeDouxやTerrence Sejnowskiが参加。Sejnowskiは長期記憶はシナプスではなくて細胞間隙のcytoskeltonに保存されているから50年経っても保たれるのだ、と大胆な説を。
■ science と PNAS が RSS feed を始めた
via ktazの論文メモ 1/6
ということで私がいまアンテナに入れてフォローしている雑誌の分野での対応状況はこんなかんじ:
- Nature あり RSS1.0 (XML)
- Science あり RSS1.0 (XML)
- Nature Neuroscience あり RSS1.0 (XML)
- Neuron まだ
- PLoS biology まだ
- JNS まだ
- PNAS あり RSS1.0 (XML)
- JNP まだ
- Cerebral Cortex あり RSS1.0 (XML)
- Nature Reviews Neuroscience あり RSS1.0 (XML)
- Trends in Neuroscience まだ
- Trends in Cognitive Science まだ
あとはScienceDirectに入っているジャーナルが対応すればほとんど網羅できてそうなかんじ。というわけで、firefoxにインストールしただけで放置していたRSS ReaderのSageにいろいろ登録したところです。
2005年01月05日
■ Nature Neuroscience 1月号
なんかfulltextの文字が小さくなってるんですけど。html読んでみると、@importなんて使っているのでinternet explorer 5ではCSS読まないようにするといった最近のテクを使っている様子なんだけど。
- Nature Neuroscience 8, 67 - 71 (2004) "Spike phase precession persists after transient intrahippocampal perturbation" Michaël B Zugaro, Lénaïc Monconduit & György Buzsáki [ris format]
- Nature Neuroscience 8, 22 - 23 (2004) "Traveling waves of activity in primary visual cortex during binocular rivalry" Sang-Hun Lee, Randolph Blake & David J Heeger [ris format]
- Nature Neuroscience 8, 24 - 25 (2004) "Discriminating emotional faces without primary visual cortices involves the right amygdala" Alan J Pegna, Asaid Khateb, Francois Lazeyras & Mohamed L Seghier [ris format]
- Nature Neuroscience 8, 107 - 113 (2004) "Morphing Marilyn into Maggie dissociates physical and identity face representations in the brain" Pia Rotshtein, Richard N A Henson, Alessandro Treves, Jon Driver & Raymond J Dolan [ris format]
- Nature Neuroscience 8, 99 - 106 (2004) "Neural population code for fine perceptual decisions in area MT" Gopathy Purushothaman & David C Bradley [ris format] NVはNature Neuroscience 8, 12 - 13 (2005) "Precision pooling predicts primate perceptual performance" Jacob W Nadler & Gregory C DeAngelis。タスクもこれの図を見れば一目瞭然。
- / ツイートする
- / 投稿日: 2005年01月05日
- / カテゴリー: [Paper archive]
- / Edit(管理者用)
2005年01月04日
■ Dorris and Glimcher (2004)とSugrue et al(2004)に関して(by uchidaさん)
uchidaさん@Cold Spring Harbor laboratoryからDorris and Glimcher (2004)とSugrue et al (2004)とに関するコメントをいただきました。許可をいただいたので以下に掲載します。今日はuchidaさんによるゲストブログということで、<blockquote>に入れないで地の文に入れます。なお、uchidaさんはリンク先をご覧になればおわかりのようにratのolfactory系によるdecisionの研究で成果を出しておられる方です。
Dorris and Glimcher論文とSugrue et al論文とを比較して、Dorris and Glimcherではchoice probabilityをexpected valueからdissociateできているのではないか、というご指摘です。これはDorris and Glimcher論文のSugrue et al論文に対するneuesを評価するにあたって重要なご指摘であるかと思います。私ももう少し考えてみるつもりですが、皆様のコメントがいただけたらと思います。ここから:
最近見付け、読ませて頂いています。こういうサイトで論文を深く掘り下げることができれば大変ためになりますね。ますますの発展をお祈りしています。以下は大部分すでに議論されていたことの繰り返しになりますが、私なりの意見を述べさせていただきたいと思います。
[Neuroeconomics]
Dorris and Glimcher (2004) および、Sugrue et al (2004) は、Barraclough et al. (2004) と共に、新しい研究パラダイムを切り開きつつあるという点で、大変興味深く見ています。ただ、3論文とも行動の解析は非常におもしろいのですが、実際に神経生理の研究という視点で見た場合、どれだけ新しいパラダイムがいかせているか、という点をもう少し考えてみる必要があるのではないかと思っています。3つの論文を比べると、その点においては、Dorris and Glimcher (2004) がもっともうまく行動パラダイムをデザインしているのではないかという印象を持ちました。
[Local fractional income and choice probability]
Sugrue et al (2004)は、matching behavior が、”local” なreward history (”local fractional income”) で説明できるということを提案したという点が非常におもしろいです。このモデルは、非常にparsimonious で、しかも従来のglobal matching に比べてmechanistic に非常にstraightforward で、その点が優れていると思います。何と言ってもglobal なvariable interval schedule を知らなくても、matching が実現できるというわけですから。
一方、Sugrue et al (2004)の限界のひとつは、”response probability”*1と、”local fractional income” が非常に相関していて切り離せないために、結局、LIP neuron がどちらをコードしているのか(このふたつのどちらかと仮定して)を決定できない点にあるのではないでしょうか。以前、Newsomeのトークを聞いていたとき、この点を質問されて、local fractional income がresponse probability をコントロールしているので。。。deep question だというようなことを言って逃れていました。
[Desirability or expected value of choice]
一方、Dorris and Glimcher (2004)がみているのは、desirability of actionあるいはexpected value of choiceで、後に述べますように、これは fractional income とは少し異なる概念です。すでにこのサイトで議論されているように、subjective vs. objective あるいは、expected utility vs. expected valueの関係、違いは、この論文の議論の弱点であると思います。しかしここでは、その点を差っぴいて、LIP neuron のactivity が結局何と相関しているのかを読む点に力点を置きたいと思います。そのために議論の厳密さが失われることも考えられますが、その点はご容赦ください。Expected value of choice と、local fractional incomeの違いは Daw and Dayan (2004) でも軽く触れられていますが、以下でもう少し考えてみたいと思います。
Dorris and Glimcher (2004)では、Nash equilibrium に達していると仮定するとふたつのchoice のexpected value (本来なら expected utility)が等価になることを利用して、expected value と、response probability を切り離すことを実験のデザインの肝としました。そして、LIP neuron は、inspection game中、response probability が変化しても(Nash equilibrium と仮定して)relative expected value of choice が変化しないときには発火頻度が変化しないが、instructed saccade trials で報酬量を変化させてrelative expected value of choiceを変化させたときにはそれに伴って発火頻度が変動することを示しました。
さて、ふたつの論文は一見似た結論に達しているように見えるかもしれませんが、全く正反対の結論に達していると言ってもいいのではないでしょうか?これは、matching task で、expected value of choice がどうなっているかを考えると明らかになります(式で考えなくても明らかだと思いますが。。。)。
[Expected value in matching task]
サルが、あるブロックでターゲットA, B (red or green)を選んだ回数を、
とします。また、そのブロックで報酬を得た回数をそれぞれ
、
とします。
すると、expected value for choice A および B は、
となります。(expected value for choiceは、一回のchioce あたりに得られる報酬量の期待値で、Daw and Dayan, 2004 で return と呼ばれているものに相当すると思います。)
ところで、このブロックで global matching が起こっていたとすると、、
をAおよびBを選んだ確率 (response probability) とすると、
が成り立つわけですが、
から、
つまり、choice A、choice B に対するexpected value for choiceが等価であることを示しています。つまり、matching task においても、relative expected value for choice がinspection game と同様の振る舞いをしている可能性が考えられます。このことは、おそらくlocal な計算をした場合でも成り立っているのではないかと想像しています。
このことからmatching task では(fig D, in Daw and Dayan, 2004にあるように)variable interval schedule を変化させても、relative expected value for choice (relative return) は変化しないと考えられます(もちろんlocal なfluctuation はあるち思われますが。。。)。従って、Sugrue et al (2004)は、積極的に、「LIP neuron は、relative expected value for choice をコードしているのではない」という結論に達する可能性も考えられます。逆に、Dorris and Glimcher (2004)は、積極的にresponse probability と相関していない点が彼らにとって重要な点です (Fig. 7)。Local fractional income とニューロンの活動が相関していないことは直接は示していませんが。。。
[trial-by-trial variability of desirability of choice]
Dorris and Glimcher (2004) では、その後、LIP neuron の細かな trial-by-trial variability が、”dynamic (local) estimate of relative subjective desirability” と相関しているかを検証しています。どちらの選択をするべきかその時々のdesirability は、opponent を演じていた computerが用いていたreinforcement learning algorithm を使って推定されています。その結果、LIP neuron の発火頻度が relative desirability と相関している、と主張しています(Fig. 9)。
では、この “desirability” とはそもそも何でしょうか? desirability は、少なくともcomputer opponent では、computer の選択をバイアスさせる値ですので、当然、desirability とresponse probability は相関しているはずです。。。従って、上で検討した response probability と LIP neuron の発火頻度を切り離したという議論がどこまで成り立つのか、あるいは、どういう形で成り立つのか、という点に疑問が残ります。そういう眼でもう一度 Fig. 6A を見てみると、確かに、各ブロックごとの平均発火頻度はほぼ変動していないように見えますが、各ブロック内でのlocal な変動に注目してみると若干response probability と相関して変動しているように見えるところもあります。単に想像に過ぎませんが、「response probability から各ブロックでの平均 response probability を差し引いたもの」を考えると、LIP neuron の発火頻度と相関しているのかも知れません(単なる読み過ぎの可能性も大ですが。。。)。
いずれにしても、global な相関(あるいは変動しないこと)と、local な相関、つまり、論文中の3つの仮説のうちのふたつ、”whenever the animals are at a mixed strategy equilibrium during the inspection game, the average firing rates of LIP neurons should be fixed ”と、”On a trial-by-trial basis, however, the mixed strategy equilibrium is presumed to be maintained by small fluctuations in the subjective desirability of each option around this fixed level caused by dynamic interactions with the opponent” の関係をもう少しきっちり詰めることが、この論文で示されたデータを読み解き、Sugrue et al (2004) との関係をはっきりさせる上で重要だと思います。その点が私にはまだはっきりつかみきれていない点でもあります。
もちろん、ひとつの領域にrelative expected value for choiceと、local fractional income をコードするニューロンが混在している可能性も考えられ、ふたつの論文は、その中の両極端のものを見ている可能性も考えられます。お互いの解析を両方のデータを使ってやって比べてみるということが必要ではないかと思います。あるいは、Sugrue et al (2004) のmatching task 中に報酬量を変化させて、local fractional income と相関した変化と、報酬量の変化に伴う相関との度合いを比べてみると、全体像がもう少し分かるのではないかと思います。例えば、Sugrue et al (2004) Fig.4でみられた相関は、Dorris and Glimcher (2004) で見ていた local なfluctuation に対応し、報酬量の変化はもっと大きなLIP neuron の活動変動を引き起こす可能性も考えられます。また、どちらの論文も population data の示し方が不十分なので、そのあたりをきっちりやればもっと何が起こっているかが良く分かったのではないかと少し残念に思います。
uchida
以上です。どうもありがとうございます。編集過程で間違いが混入していたらお知らせください。ひきつづき私もコメントを書く予定です。
- / ツイートする
- / 投稿日: 2005年01月04日
- / カテゴリー: [価値による行動選択 (expected value)] [神経経済学 (neuroeconomics)]
- / Edit(管理者用)
# Gould
ああ、uchida師匠!ついに僕の尊敬する人々がこの日記に集結することに・・・離れた場所にいる、こんな豪華なメンバーで議論がなされているとは、blogの一つの理想型を見ているように思います。ますます見逃せなくなりました。pooneilさん、実のないコメントで申し訳ありません。1年待って下さい。そうしたら、僕もここの議論に少しでもお役に立てるようになります。精進します。
# mmrluchidaさん、ご無沙汰しております。
matcing taskでもInspection game同様にexpected value for choiceが変動しないのではないか、という議論は確かにその通りであり、だとすると、Sugrue et al 2004 とDorris and Glimcher 2004は同じ領域からまったく違う細胞を記録したことになるというご指摘、すばらしい。
以前、計算したようにVI-VIではあるchoiceのresponse probability を下げれば下げるほどexpected value はあがり、response probability を上げればexpected valueが下がる。自然と報酬が得られる確率が自らのresponse probability に連動するような形で入っているから、これはゲームと同じ。ゲームでは、相手が自分のresponse probability をlocalに見て、それを元に相手側の行動(ここではreward probability)を変動させ、それがexpected valueを変化させる。最終的にたどり着く先はequilibrium、すなわちそれぞれのexpected value for choicesが等価になるが、これはGlobal matchingで得られる解と同じという計算には、目からうろこが落ちました。
Dorris and Glicmcher でもlocal にはそのfluctuation が神経細胞活動に反映されているように見えるところもあり、本当のところは互いのデータを互いの方法で解析するか、Sugrue側のタスクで報酬量を変動させたcontrol taskを用意するかしないとわからない。
なるほど、鋭いご指摘です
結局、choice probabilityとexpected value for choices
を分離するには、
1. choice probability 変動, expected value 固定
2. choice probability 固定, expected value 変動
の両方の課題を行って神経細胞がどっちに相関を持つのかを特定すればよい。1はVI-VIやinspection gameでできるとして、2は両者でできているのか?
Platt and Glimcher 1999の課題ではchoiceはさせていないので、これでコントロールを取ったというDorris and Glimcherはダメ。
やはりSugrueのようにVI-VIで量を変動させるのが最も近道でしょうか?
と、uchidaさんの話を繰り返しまとめただけで、私はなんのコメントにもなっていませんね。もうすこし考えよう....
# pooneilGouldさん、まさにit's a small worldですね。
mmrlさん、重複分を削除しておきました。システム変更のためにお手数かけてしまい、恐縮です。
見当違いで袋叩きにあうかと思っていましたが、少し安心しました。よく分からない点は、Dorris の強化学習アルゴリズムと、Sugrue のモデルがどれだけ似ているものかという点です。もしほぼ同じであれば、ふたつの論文は、local な変動という点ではほぼ同じ物を見ていて、Sugrue がglobalにはそれほど変動しないことを見落とした、という結論になる可能性も考えられます。ただ、Sugrueのモデルはglobal matchingをうまく説明できるという点を考えると上の可能性はあまりあたらない気もします。一方、Dorrisの強化学習アルゴリズムがglobalに動くとしたらそもそもdesirabilityと呼ばれているものは何なのかという疑問が出てきます。
Sugrue et al (2004)へのコメントとして、Daw and Dyan (2004) では、"Several questions arise. First, this task has deeper psychological than computational roots. The field of reinforcement learning has focused on a different class of task, which allows for choices to have delayed consequences. "とあります。では、Sugrue et al の model と強化学習のモデルの違いの本質はどこにあるのですか?このあたりは mmrl さんや pooneil さんが詳しそうですね。コメントを頂ければ大変嬉しいです。
なお、mmrl さんの下の段落は、expected value を local income (or local total value) とした方がすっきり行くのではないかと思います。
「以前、計算したようにVI-VIではあるchoiceのresponse probability を下げれば下げるほど local income はあがり、response probability を上げれば local income が下がる。自然と報酬が得られる確率が自らのresponse probability に連動するような形で入っているから、これはゲームと同じ。ゲームでは、相手が自分のresponse probability をlocalに見て、それを元に相手側の行動(ここではreward probability)を変動させ、それがlocal incomeを変化させる。最終的にたどり着く先はequilibrium、すなわちそれぞれのexpected value for choicesが等価になるが、これはGlobal matchingで得られる解と同じという計算には、目からうろこが落ちました。」
ところで、これだけ議論されてもますます面白い、そういう論文が書いてみたいですね。。。
# uchida自分のコメントへの訂正。
「以前、計算したようにVI-VIではあるchoiceのresponse probability を下げれば下げるほど local income は下がり、response probability を上げれば local income が上がる」
これがmmrlさんの意図したものと違っていれば申し訳ありません。
# RyoheiんSorry in English, but I cannot read this diary with my w3m, which I usually use for writing Japanese.
This might be minor point, but Nao(Uchida-san)'s statement (R_A/N_A = R_B/N_B) is not generally true for the leaky-integrator model.
In the model, P_A(t) is given by Int dt' pR_A(t')exp(-t-t')/tau (Int: integral, pR_A: probability to have income from A). In other words, there is a delay in P_A(t) response to a certain change of pR_A. Thus the change of R_A causes a transient change in the expected value for choice A, pR_A(t)/P_A(t), for a period of tau. In this period, the pR_A(t)/P_B(t) should not equal to pR_B(t)/P_B(t) generally. If pR_A(t) changes continuously, the expected value for choice also changes continuously.
I am not sure how does it affect the whole discussion, though .
By the way, a happy new year, folks !
# pooneilryasudaさん、movable typeは書き込みのときにJavaScriptを使っているのでw3mやlynxでは書き込めないんですよね。お手数かけます。w3mで読むときはいかがでしょうか。Lynxではとりあえずメインページは読めるようなのですが過去ログを見るのに不便があるようです。
# Ryoheiん(Further thought from the last comment)
Note that the time course of the expected value for choice (E_X(t):X = A, or B) is a first derivative of pR_X(t) blured by a filter with decay constant of tau. Thus obviously these two values are tightly relate: just a integrator (neuronal?) circuit can translate R to E.
I think the Nash equilibrium would take about the same time as the leaky-integration time (tau). So, probably the stiation may be the same in the other paper too.
Pooneil-san: I know this is my problem sticking to the old-fashioned text browser, but I cannot read Japanese text in this site (MOJIBAKE shimasu).
# RyoheiしIt seems like several typos in my last comment.....
Anyway, I had a brief chat with Nao, and I think both of us agreed that the expected value for choice is time dependent. Interestingly, it is a bit tricky to define the time-dependent expected value, because expected value is statistic value. If a process is not in an equilibrium, ensemble statistics does not equal to time-averaged statistics any more.
I am looking forward to pooneil-san's further comments !!
# mmrluchidaさんのコメントに関して
Daw が言っている`` The field of reinforcement learning has focused on a different class of task,..''の意味についてですが、強化学習では系列をなした一連の行動の後に報酬が与えられ、その系列行動を強化するような学習も含むと言うことだと思います。
このような問題では、choiceした後の直近の報酬のみではなく、将来にわたって得られる報酬の合計を最大化するようにchoiceをしなければならない。本来は、1回の試行におけるdecision が状況を変化させ、次の試行以降における報酬に影響するような(Tanaka SC et al 2004等)のタスクを使わないと、こういった将来の報酬に関する活動は見れません。Sugrue et al にしてもDorris & Glimcherにしても、得られる報酬の量や確率が1回のchoiceのみに依存して決まっている。扱っている問題が強化学習の分野で言うimmidiate reward のタイプの課題を使っていますので、その意味でdifferent class of taskなのだと思います。
では、このimmidiate reward での強化学習モデルとSugrueが使ったモデルの本質的な違いはなにか?
強化学習モデルと言ってもいくつかの学習モデルが考えられ一概には言えないのですが、重要な点は単位時間に得られる総報酬を最大化しようとするのが強化学習モデルであって、Sugrueが使っているのは単なるMatchingの変形版に過ぎないので、必ずしも総報酬が最大になるとは限らない。
でもSugrue et al 2004のnote 19 で言っているように、動物の行動を説明するのにたいした違いはないっていってますね。``we make no clain that our fractional income model captures the ultimate computation going on inside the animal's brain. The model is descriptive not mechanistic --''
なーんて開き直ってますが、おいおい、おめーさん心理学じゃなくて神経科学やってんじゃねーのか!と突っ込みたくなります。
私のコメント「以前、計算したようにVI-VIではあるchoiceのresponse probability を下げれば下げるほどexpected value はあがり、response probability を上げればexpected valueが下がる。」
expected value をDawの言うreturnと同じものだと思えばこのままでよい。各行動をしたときに得られる報酬の確率の意味で書いています。
VI-VIの場合、理論的には選択しないとそこに報酬が存在する確率は増えるって図を7月1日あたりに乗せてもらった思うのですが...pooneilさん、引越しするときに消えてません?
これに対してlocal incomeは単位時間あたりの報酬確率のlocalなものなので、responce probability が下がれば同様に下がりますから、内田さんの言うのもまた正しい。
もうすこし厳密なことがいえるような計算をいまちょっとしてますので、お待ちください。
また、Dorris の強化学習モデルによるゲーム課題とVI-VIでの報酬確率の変動の関係は、定性的には同質であることは直前のコメントで述べましたが、厳密には違うはずで、どこがどのように同じでまた違うかは検討を要します。こちらも時間をください。
# uchidaryasudaさん、mmrlさん素晴らしいコメントありがとうございます。直感的な思考ではなく、実際に数式やsimulationで考えないと良く分からないところも多いですね。
mmlrさん、確かに、VI (Poisson)では、そちらを選択しないうちに、expected value は上がりますね。そういう意味だとは気付いていませんでした。これは、VI-VIの奥の深いところで、Newsomeらも”natural environment” と言っていますが、たとえば、木の実が熟すというようなことを考えれば、一回食べ尽くしても、時間が経つうちにまた訪れてみる価値が上がるという「奥の深い」現象ですね。そういう意味では、ethological な視点からもおもしろい現象です。おそらく、生物が得意とするべく進化してきた、そういう背景もありそうです。
人々がどういう意味で強化学習という言葉を使っているかは勉強したいと思います。
続報も楽しみにしています。私ももう少し詳細を考え直してみます。
# pooneilお返事滞っていて申し訳ありません。mmrlさん、消えた図の件ですけど、直しておきました。6/31というありえない日のエントリだったもんでいじってる過程で消えてしまったようでした。ではまた。
# pooneil私のコメントは新しいエントリに書きました。1/10のところをご覧ください。このエントリも長くなってきたのでコメントは新しいほうに書いていただいたほうが埋もれないかと思いますのでよろしくお願いします。
2005年01月03日
■ JNP 1月号
E. J. Tehovnik, W. M. Slocum, C. E. Carvey, and P. H. Schiller "Phosphene Induction and the Generation of Saccadic Eye Movements by Striate Cortex" J Neurophysiol 93: 1-19, 2005 [EndNote format]
ここ数年V1のMicrostimulationをやってきたE. J. Tehovnikによるレビュー。これが重要なのは、William Dobelleがやっているような人工視覚の応用と大いに関連があるからです。William Dobelleに関しては稿を改めていつか語りましょう。
んで、このレビューはここ最近Tehovnikがやりつづけている、V1へのmicrostimulationによって起きているであろうphospheneの生成に対してnonhuman primateがどのようにして応答するかを調べた一連の仕事についてまとめています。
はじめに彼がやったのは、二つの刺激刺激を出して刺激の出現時間を変えてやることでどちらの視覚刺激を選択するかを操作してやり、microstimulationによって選択がどうバイアスされるかを調べたもの。しかしこれはNewsomeとかがやっているperceptual decisionと似たようなもので、そんなに面白くはない。
重要なのはmicrostimulationによるphospheneを視覚刺激とどのくらい混同して、microstimulation単独の条件でphospheneへサッケードするかどうか、というあたりであって、そのへんに関するタスクのデザインが重要なのだと思うのだけれど、タスクとしてはしょぼい。あくまでこの人はmicrostimulation屋さんなのです。すくなくともいまのところ。
むしろこの人がいまのところいちばん得意としているのは、microstimulationのパラメータを調節していかにカラムレベル以下の小さな領域を刺激できるようにしているか、というあたりで、ここにかんして参考にすべきかと思われます。たとえばNewsomeの実験なんかでも1秒間とかmicrostimulationしっぱなしだったりして、いったいどこが刺激されているか(MTの方向カラムどころかMT外まで繋がるネットワークを刺激している可能性がある)さっぱりわかりません。同様なことはTirin MooreやGrazianoなんかあたりでも該当することでしょう。いっぽう、Tehovnikはfineですよ。刺激の効果を片目からの入力だけに限局するのに成功してたりする。つまり、ocular dominance columnの片方のほうだけを刺激しているといえるようなデータを持っているのです。
この仕事といまAOPになっている David C. Bradley, Philip R. Troyk, Joshua A. Berg, Martin Bak, Stuart Cogan, Robert Erickson, Conrad Kufta, Massimo Mascaro, Douglas McCreery, Edward M. Schmidt, Vernon Towle, and Hong Xu "VISUOTOPIC MAPPING THROUGH A MULTICHANNEL STIMULATING IMPLANT IN PRIMATE V1" J Neurophysiol (September 1, 2004) [EndNote format]、これらとhumanでのV1 microstimulationとをつなげる…ああもう誰かやってるんだろうなあ。
P. H. Schiller@MITと連名で論文を出す前からMITには所属しているみたい。私が知っているのは1996年のJ Neuroscience Methods("Electrical stimulation of neural tissue to evoke behavioral responses.")だけど。
レビューに関連するTehovnikの最近の仕事のリスト:
- European Journal of Neuroscience Volume 16 Issue 4 Page 751 - August 2002 "Differential effects of laminar stimulation of V1 cortex on target selection by macaque monkeys" Edward J. Tehovnik, Warren M. Slocum and Peter H. Schiller
- Experimental Brain Research Issue: Volume 148, Number 2 Date: January 2003 Pages: 233 - 237 "Microstimulation of macaque V1 disrupts target selection: effects of stimulation polarity" Edward J. Tehovnik and Warren M. Slocum
- European Journal of Neuroscience Volume 17 Issue 4 Page 870 - February 2003 "Saccadic eye movements evoked by microstimulation of striate cortex" Edward J. Tehovnik, Warren M. Slocum and Peter H. Schiller
- European Journal of Neuroscience Volume 18 Issue 4 Page 969 - August 2003 "Behavioural state affects saccadic eye movements evoked by microstimulation of striate cortex" Edward J. Tehovnik, Warren M. Slocum and Christina E. Carvey
- European Journal of Neuroscience Volume 20 Issue 1 Page 264 - July 2004 "Microstimulation of V1 delays the execution of visually guided saccades" Edward J. Tehovnik, Warren M. Slocum and Peter H. Schiller
- European Journal of Neuroscience Volume 20 Issue 6 Page 1674 - September 2004 "Microstimulation of V1 input layers disrupts the selection and detection of visual targets by monkeys" Warren M. Slocum and Edward J. Tehovnik
European Journal of Neuroscienceに出しつづけてレビューをJNPに出すというものすごく渋い仕事ぶり。見ている人はちゃんと見ている、ということでもあるのだけれど。
- / ツイートする
- / 投稿日: 2005年01月03日
- / カテゴリー: [視覚的意識 (visual awareness)]
- / Edit(管理者用)
2005年01月01日
■ あけましておめでとうございます
- あけましておめでとうございます。今年もよろしくお願いします。現在実家に帰っております(いるはずです)。このエントリは投稿日の指定機能を使って公開してみました。うまくいくかどうか。
- と書いたらうまくいかないでやんの。というわけであらためてあけましておめでとうございます。今年もよろしくお願いします。
- 実家のinternet explorer 5でこのサイトを見たらいろいろひどい。H1タグがアホみたいに大きいし、過去ログの選択だけ字体が行書になってるんです。なかなか難しい。
- 子供たちと近くの川沿いの大きな公園に行って凧揚げをしました。はじめて凧揚げをする息子はなかなかコツがわからないようですぐにあきらめて他の遊具で遊びだしたので私がやってみました。風が強いのですぐに揚がります。ちょうど凧と太陽が重なってサイケデリック。ま、自然が一番サイケデリックであるなんてのは当たり前なのだけれども。雲の複雑な形とか、葉っぱのすべて落ちた木の枝振りとか。んでもって、だんだん凧揚げの感覚を思い出してきます、凧の動きを見ながら凧の周りで吹いているだろう風を感じて、凧糸一本でそれに最小限の介入をする、凧は地面とほとんど垂直になるくらいに揚がって、風に対する抗力よりは揚力の方が優勢になったのを感じます。小学校の時に叔父さんの手製の凧を持参した凧揚げ大会で同じ河原(そのころはいまのような綺麗に整備された公園ではなくて、本当に堤防の内側の河原だった)で誰よりも高く凧を上げることが出来たことを誇らしく思い出してみたりして。そうこうしているのを見て息子がまたやりたくなったようなので、今度は息子が揚げている横でいろいろコツを教えてみます。あんまり無駄に走らないとか、糸が弛んだときだけ凧糸を引くとか、さかさまになって落ちてきても凧糸が弛んでいなければ凧が自分で体勢を立て直すから平気、とか。最後のコツは息子が気に入ったようすで、わざと凧が落ちてくるぎりぎりまでもっていってから急上昇させるような技を開発して「つばめ返し」と命名するまでに。そのうち息子は放っておいても凧揚げが出来るようになってきたので、今度は娘と揚がっている凧の影を追っかけて遊びます。でも娘はすぐに飽きる。まだ小さいのでしょうがないのだけれど。私の父親(子供たちのおじいちゃん)も自作した飛行機(バルサと発泡スチロール製)をいっしょうけんめい調整してました。私も持参した論文を読む事もなく、凧揚げが面白くなってきた息子とけっきょく1時間半付き合うことに。そんな正月でした(<-まだ終わってない)。
お勧めエントリ
- 細胞外電極はなにを見ているか(1) 20080727 (2) リニューアル版 20081107
- 総説 長期記憶の脳内メカニズム 20100909
- 駒場講義2013 「意識の科学的研究 - 盲視を起点に」20130626
- 駒場講義2012レジメ 意識と注意の脳内メカニズム(1) 注意 20121010 (2) 意識 20121011
- 視覚、注意、言語で3*2の背側、腹側経路説 20140119
- 脳科学辞典の項目書いた 「盲視」 20130407
- 脳科学辞典の項目書いた 「気づき」 20130228
- 脳科学辞典の項目書いた 「サリエンシー」 20121224
- 脳科学辞典の項目書いた 「マイクロサッケード」 20121227
- 盲視でおこる「なにかあるかんじ」 20110126
- DKL色空間についてまとめ 20090113
- 科学基礎論学会 秋の研究例会 ワークショップ「意識の神経科学と神経現象学」レジメ 20131102
- ギャラガー&ザハヴィ『現象学的な心』合評会レジメ 20130628
- Marrのrepresentationとprocessをベイトソン流に解釈する (1) 20100317 (2) 20100317
- 半側空間無視と同名半盲とは区別できるか?(1) 20080220 (2) 半側空間無視の原因部位は? 20080221
- MarrのVisionの最初と最後だけを読む 20071213