[月別過去ログ] 2005年12月
« 2005年11月 | 最新のページに戻る | 2006年01月 »2005年12月29日
■ 「行動の価値」を表す線条体ニューロン
Science 11/25 "Representation of Action-Specific Reward Values in the Striatum"
最終回。まとめ、というか落ち穂拾いというか。
いろいろ文句を付けてきましたが、striatumにaction valueをコードしているニューロンのpopulationがある、ということに関してはじゅうぶん証拠があると思います。その根拠としては、本文でのQ_RやQ_Lのコーディングよりはsupporting materialでのinstantaneousなQ_R(i)やQ_L(i)でのregressionのほうが説得的だと私は思うのですが。
また、このストーリーの正しさは、つづいで出てくるであろう論文によって確認されることでしょう。今回のScience論文はdelay期間(レバーをホールドしてからgoシグナルが出るまで)のactivityだけに注目していましたが、今年のSFNで著者らは同じニューロン記録でmovement期間(レバーを倒している時間)やreinforcer期間(rewardをもらっている時間)の活動を解析して報告しています。それによると、delay期間でaction valueをコードしているニューロンがmovement期間にactionをコードしてたりすることはないようで、striatumのニューロンはaction value, action, reinforcerをコードするニューロンは別々の集団らしいと。(まだジャーナルには出てきていない結果なのでこのくらいあっさりめにて。)
また、Doyaモデルの検証という意味では、striatumでのaction valueの情報が、その下流のGP/SNrでselected actionに変換される、という図式を証明するために、GP/SNrからの記録データが出てくることを期待します。action valueに関してはstriatum > GP/SNr、selected actionに関してはstriatum < GP/SNrとなれば説得力があります。Science論文でもHagai BergmanのJNS '04 "Independent Coding of Movement Direction and Reward Prediction by Single Pallidal Neurons"をreferしてますが、この論文ではGPeニューロンは主にselected actionをコードしています。ただ、free-choice taskではないので(cueによってtargetの出る位置が決まっていて、reward probabilityが確率変動する)、やはりここは直接的な検証が必要です。
なお、Science論文のdiscussion部分を読んでいると、selected actionが下流のGPe/SNrでコードされるのか、それともlateral inhibitionによってstriatum内の別のニューロンによってコードされるのか、は検証の必要あり、としていて、含みを残していることがわかります。
あとついでに、discussion部分の最後の一文になっていきなりParkinson's diseaseが出てくるあたりには、とってつけた感をおぼえたり。というか前の文とつながってないし。
以上です。
Postscript: これまでのSugrue論文とかGlimcher論文とかのときにはそれなりにメイザーの教科書読んだり、ゲーム理論について勉強したり、周辺領域の勉強をして臨んだのですが、今回は強化学習まわりまで踏み込めませんでした。すくなくともactor criticモデルとQ-learningモデルとの本質的な違い(on-policy TDとoff-policy TDの違いあたり)は押さえとかないと、と思ってSutton and Bartoの教科書のhtml版とか、NISS2000のテキスト(pdf)および講義録(pdf)とか、いくつかダウンロードしておいたのですが、そのまま放置してしまいました。んで、手癖で、統計解析まわりに文句付けて流してしまった、という次第です。読んでくださった方、どうもありがとうございました。(いや、まだこのブログは続きますけど、なんかそう言って締めたいかんじ。)
- / ツイートする
- / 投稿日: 2005年12月29日
- / カテゴリー: [行動の価値 (action value)]
- / Edit(管理者用)
2005年12月28日
■ 忘年会
線条体論文の締めにたどりつけてないけど、年内にはなんとか。
3次会はひさびさにカラオケ。DAMは曲数が多かったので感激して趣味全開で選ぶ。TPOとかなし。すんません。
- 「冬の散歩道」 サイモン アンド ガーファンクル(「冬」ネタしばりということで。ほかの皆さんは「冬の稲妻」だったり、「津軽海峡冬景色」だったり。)
- 「無限グライダー」 アジアンカンフージェネレイション ずっとサビは「無限グライダー 有限 it's my world」って歌ってるのかと思ってたから驚いた。「無限? ゆらいだ 有限 つまりは」だったのか。それとも「はいからはくち」みたいなもん?
- 「歌声よおこれ」 サンボマスター
- 「サーフズ アップ」 ザ ビーチ ボーイズ 一番高いところの声も出たよ!
- 「ストライク」 スネオヘアー
時間があればエレカシの「ガストロンジャー」を歌うつもりだったけどタイムアップ。こんど歌うときまでにレミオロメンの「粉雪」をおぼえておく予定。
2005年12月21日
■ 「行動の価値」を表す線条体ニューロン
Science 11/25 "Representation of Action-Specific Reward Values in the Striatum"
線条体の論文に戻りましょう。Supplementary dataのp.11-12でselected actionをどのくらいコードしているかの議論をしています。はじめのパラグラフは、reward probabilityをcollapseして、ノンパラでhigh valueへのactionとlow valueへのactionとでの有意差検定をしています。これはchoice probabilityがvalueと相関しているから行ったのでしょう。あと、右と左との間の検定ではないのです。ともあれ、reward probabilityをcollapseした点において、有意性が出にくくなるわけで、これまで指摘してきた、同時にfittingしてないという問題をここでも抱えています。いちばんフェアなのは、Q_L、Q_R、action{R,L}で同時にfittingしておいてから、それぞれのregressorのR-squareを計算することでモデルへの寄与の大きさを定量化してやることだと思うのです。ちと同じことに絡みすぎましたのでこのへんで。
お次はFig.4に関して。GlobalなQ_R、Q_LではなくてtrialごとのinstantaneousなQ_R(i)、Q_L(i)を計算してやって、行動およびニューロンのデータと関連づけています。(Sugrue et alやDorris and Glimcherとの対応を付けるならば、これまでのQ_RやQ_Lがglobalなtime scaleでのvalueであり、Q_R(i)やQ_L(i)がlocalなvalueになります。) このparticle filterを使ったベイズ推定によるQ_R(i)、Q_L(i)の推定、というやつはadvances in NIPS 2004ですでにpublishされていて、ダウンロード可能です。SugrueのときなんかglobalなvalueよりはlocalなvalueのほうがLIPニューロンではコードされていたわけで、instantaneousなQ_R(i)、Q_L(i)を計算してやることでstriatumのニューロン発火をよりよくfitting出来るのではないかと予想するわけです。Fig.4および本文に出てきているのは1個のニューロンのデータだけですので、suppelementary dataの方を見ると、p.10-11に記載があります。有意なニューロンの数だけで考えると、Q_RやQ_LとQ_R(i)やQ_L(i)とでは差がないようです。
これはLIPニューロンとは違っていておもしろいかも、と言いたいところですが、これまで指摘した点と併せて考えてみると、instantaneousなvalueで見たほうが真実に近いのではないでしょうか。これまで指摘してきた、selected actionの寄与に関してもこちらは正当にモデル化されている(supplementのp.4)と言えると思います。逆に言えば、こちらのモデルを使って、Q_R(i)、Q_L(i)をregressorとしたときの説明率(R-suqare)とselected actionをregressorとしたときの説明率とを比較して、前者の説明率が高いことを示せれば、より強い証拠だったと思います。一方で、Fig.4Bにもあるように、Q_R(i)>Q_L(i)のときにはほぼ常にRを選んでいるわけで、multicollinearityの問題はさらに深刻になることも予想されます。このへんは、VR-VR concurrent reinforcement scheduleを使っているが故に、classicalなmatching lawが成り立たない(choice probabilityは横軸にlocal valueをとると、step関数的になる)ことの弱点、とも言えます。後知恵ですが、Sugrue et alでVI-VIを使うことでmatching lawが成り立つようにしたことは、前回のエントリの上図のCやDの部分のデータを確保することにも役立っていたのだな、とわかります。
書いていることがだらけてきました。つぎくらいでまとめたいと思います。
- / ツイートする
- / 投稿日: 2005年12月21日
- / カテゴリー: [行動の価値 (action value)]
- / Edit(管理者用)
2005年12月19日
■ 「行動の価値」を表す線条体ニューロン
Science 11/25 "Representation of Action-Specific Reward Values in the Striatum"
課題がfree-choiceであることが"value"のコードを議論するにあたってどうして重要なのか、という点について。Nature Review Neuroscienceの"CHOOSING THE GREATER OF TWO GOODS: NEURAL CURRENCIES FOR VALUATION AND DECISION MAKING." Leo P. Sugrue, Greg S. Corrado and William T. Newsomeでは、free-choice taskでないこれまでのtaskでは、(1) rewardがrewardのあるなしのような二値的関係にあって、parametricになっていないこと、(2) rewardとchoiceとが1対1対応になっていること、の二点においてvalueからchoiceへの変換を扱うにあたっては限界があったと指摘しています(p.367)。
This approach is fundamentally limited, because the value transformation in such tasks is rudimentary (the probability of reward is unity for the instructed behaviour, and zero for all others), and the 'decision' is a simple one-to-one mapping between this representation and choice.
裏返せば、free-choice taskの利点とは、(1) reward probabilityを0-1の間で確率的にふることでparametricに扱うことが出来る、(2) rewardとchoiceとが1対1対応になっていない、つまり、low valueのときでもchoiceをしているtrialのデータを得ることが出来る、ということにあります。
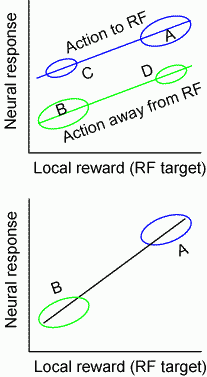
イメージをつかみやすくために、Nature Review NeuroscienceのFig.6dおよび、Sugrue et. al.に対するDaw and DayanのperspectiveのFigure A-Cを元にして図を作ってみました。Sugrue et. al.のデータを想定しながら見てください。上の図は、ニューロンの発火を横軸のlocal reward(右へ行くほどRFのreward量=valueが大きくなる)でプロットしたもので、青がpreferredな方向へのactionで、緑がnonpreferredな方向へのactionとなります。Free choice taskの良いところは、上の図でのCやDに対応する行動とニューロンのデータが取れるところにあるわけです。もし、このCとDとのデータがなかったとすると、下の図のようになります。こうなると、reward量とactionとを分離して扱うことができないので、ニューロンがvalueをコードしているのか、actionをコードしているのかわからなくなるわけです。
というわけでfree-choice taskの利点は明確なのだけれども、上図にあるCやDのようなデータはAやBと比べて少なくなり、データは汚くなります。Nature Review NeuroscienceのFig.6dを見ていただければわかりますが、ほんとうにAとDとが分離しているか、BとCとが分離しているか、と言われるとspecimenにしては、けっこう微妙なところです。この点が前にわたしが書いた難点の一つです。行動選択率はvalueと正の相関を示すため、Aと比べてCのデータ数は必ず少なくなる。そのため、データは比較的汚くなりがちで、actionとrewardとのそれぞれの寄与を定量化するには慎重な統計的手続きが必要になる、というわけです。これはfundamentalな難点ではありません。データ量をたくさん取って、きっちり検定をかければいわけです。しかし、single-unitの難しさでデータが少ないところを強引に解析して乗り切っているように思えます。(Sugrue et. al.でもこの上図のようなデータに関してANCOVAをすべきところでたんに緑線、青線のslopeの有意度を示すだけで乗り切っています。)
今回の線条体の論文でも、上図のCやDに対応するデータが少ない上に、上図のようにrewardとactionとを明示的かつ同時にfittingすることを避けているように見える点がどうも気になるわけです。
- / ツイートする
- / 投稿日: 2005年12月19日
- / カテゴリー: [行動の価値 (action value)]
- / Edit(管理者用)
2005年12月14日
■ 神経科学雑誌の投稿規定まとめ
まだ小休止。ryasudaさんのところに書いたコメント関連で。
投稿する雑誌ごとに論文の投稿規定があって、文字数が決まっているのだけれど、だいたいオーバーするものです(前回のエントリーにも書きました)。そこでどうするかというのが問題なのですが、投稿規定を守って文章削ってから投稿するか、必要なロジックと情報を全部入れて通ってから削ればよいとするか、ということになります。だいたいは大目に見てもらえるくらいにオーバーしている程度に必要なことは盛り込んで投稿する、ということになるでしょう。どのくらいオーバーしても大目に見てもらえるかの見積もりが人によって違いそうですけど。あと、オンラインの投稿システムとかで厳密に文字数が決まっているとこの技が使えないのだけれどどうなんだろ。
ということで、つい、投稿規定を調べてしまったのでいくつかメモ。2005年の12月13日現在ということで。もっといろんな規定はあるけど、原稿のスタイルについてだけです。ほかの雑誌について知ってる方は補充を。とくに最近投稿した人はオンライン投稿システムで気づいたこととか教えてください(上記の文字数などのソフトウェアレベルでの制限とか)。
[Nature]
Formatting guide: manuscript preparation and submission- They do not normally exceed 5 pages (One page of undiluted text is about 1,300 words.)
- no more than 50 references
- a summary, separate from the main text, of up to 150 words
- They do not normally exceed 4 pages (One page of undiluted text is about 1,300 words.)
- no more than 30 references
- a fully referenced paragraph, ideally of about 200 words, but certainly no more than 300 words
Article
Letters
-
[Science]
General Information for Authors いま気づいたけれど、ScienceはもはやMaterials and Methodsはsupporting online materialに入れる、と明示してあるのね。 - up to ~4500 words or ~5 journal pages
- up to 6 figures or tables
- a maximum of 40 references
- up to ~2500 words or ~3 journal pages
- up to 4 figures or tables
- a maximum of 30 references
Research Articles
Reports
-
[Nature Neuroscience]
Contents type - 2,000-4,000 words (excluding abstract, Methods, references and figure legends)
- no more than 8 display items (figures and/or tables)
- Abstract typically 100-150 words
Article
-
[Neuron]
Information for Authors - under 65,000 characters (including spaces, figure legends, and references)
- no more than 8 figures
- A single paragraph of fewer than 150 words
Article
-
[PNAS]
Information for Authors - six printed pages or 47,000 characters, including all text, spaces, and the number of characters displaced by figures, tables, and equations.
- Abstract. no more than 250 words
Article
-
[JNS]
Organization of the Manuscript - an abstract (not to exceed 250 words)
- an introductory statement (without heading; not to exceed 500 words)
- a description of the experimental procedures or methods, description of the results, a discussion of the experimental findings (not to exceed 1,500 words)
- References, limited to approximately 60
- ここは規定の遵守を厳しめに書いてます。"Submitting an incomplete manuscript or a manuscript that does not adhere to these limits will cause a delay in publication, and possible review."
Article
-
[JNP]
Instructions for Preparing Your Manuscript - Abstract: one-paragraph abstract of not more than 250 words
Article
ここまでで力尽きた。JNP要補充。Cerebral Cortex、PLoS biologyなども加えておきたいのだけれど。
2005年12月13日
■ 小休止で余談
線条体の話はまだ続きますが小休止。
月曜日にjournal clubで扱いました。SugrueのNature Review Neuroscienceの流れに組み込んで、SugrueのScience、Dorris and GlimcherのNeuronと併せてNeural correlate of valuationということでやってみたのだけれど、詰め込みすぎて失敗。Free-choice taskを使うことの意義(valuationとactionとの一対一対応を外す)と、その難しさ(valuationとactionとを分離することに起因する難点)とを説明したかったのだけれで、そこへ行く前にtaskの説明をするだけでいっぱいいっぱい。
これまた余談だけど、彦坂研のNature '02の本文の第一文はこう:"Reward shapes goal-oriented behaviour." めちゃかっこいい。「破戒」の出だしの名文「蓮華寺では下宿を兼ねた。」これに通じるような。文章が短くて、しかも主語、動詞、目的語の全部に情報があって、ムダな言葉(指示語)がないわけです。こういう締まった文章で始まる論文を書きたいものです。わたしはキャラ的にクドいもんで、こういうあっさりさに欠けるだけに、そうありたいなという気持ちは強い。
あと、NatureやScienceっぽい出だしでいいな、と思うのは、"Suppose that ..."とか"Imagine that ..."みたいなかんじではじめて、日常生活でだれもが持っている経験(記憶はあるのに名前だけ出てこない"tip-of-tongue"現象とか、時計に目を向けると秒針が一瞬止まったように見える現象とかね)を採りあげて、それのneural correlateを明らかにしました、みたいなやつね。
ムダだと思うのは、"It has been recognized that ..."とか"A number of studies have shown that ..."(って自分の論文かよ!)とか、情報がほとんどない前置き。
長くなるのはしょうがないところがあります。著者としてはいろんな断り書きを付けたいものですから。よくないんだけれど。科学論文はおもしろいことの書いてある読み物であるべきなんだけれど(NatureやScienceに関しては明確にそう)、いっぽうで法律の文書的に、あれは言った、これは言ってない、ということを厳密に記した文章なのですね。だからつい、あれこれ断り書きを付けだくなる。「われわれは現象Aがおこることを見つけた。」が「われわれは条件Bのときに現象Aを見つけた。」になって、「われわれは条件Bのときに現象Aを見つけた。条件Cのときには現象Dが起こることを見出した。」になって、この二文の関係をあたかも関連のある現象であるかのように見せるために(ロジカルには正しくないときに使うズルテク)、「われわれは条件Bのときに現象Aを見つけた一方で条件Cのときには現象Dが起こることを見出した。」とかにしてどんどん文章が長くなってゆくわけです。
まあ、すべてのことにはトレードオフがつきものであり、私たちはパラメーターが多すぎる問題を適度なタイムスケールである程度マシなやり方(思いついた限られた選択肢の中で選んだマシな方であり、最適化された、とは言わない)でもって処理する。そういうわけです。それがむずかしい。お、強化学習ネタ。
つれづれと。
2005年12月08日
■ 「行動の価値」を表す線条体ニューロン
Science 11/25 "Representation of Action-Specific Reward Values in the Striatum"
前回はあくまで統計上の手続きに関して議論しました。そのような議論とはべつにして、じっさいのところcaudateニューロンがselected actionをコードするだろうか、という問題に関しては、これまで出版されたほかの論文を読むことから推測することができます。というわけで彦坂グループのNature '02 "A neural correlate of response bias in monkey caudate nucleus"をあたってみます。まえにKawagoe et.al.に言及しましたが、今回の論文との対比という意味ではNature '02の方を考える方が妥当でした。
Nature '02の課題は2afcのvisually-guided saccade taskで、20trialブロックごとに二つのreward contingencyの条件[右reward+ 左reward-]と[右reward- 左reward+]とが交代します。Saccadeのtargetが出る前のanticipatoryなactivityに注目します。Saccadeのtargetが右に出るか左に出るかはtargetが出るまで不明ですから、このanticipatory activityはmotor preparationによるものではありません。すると、caudateニューロンのanticipatory activityはrecording siteのcontralateral visual fieldにrewardが出るときに強く発火しました。このactivityはじっさいに右にサッケードしたか、左にサッケードしたかには依存しません。よって、このactivityはsaccadic targetのreward valueに基づいたresponse bias(reaction timeの違いとして出てくる)を反映している、というのがこの論文の結論です。
というわけで、caudateのニューロンがselected actionではなくてaction valueをコードしている、というのは尤もらしいように思えます。いっぽうで、このNature '02と比べての今回のScience '05のノイエスを議論する必要があります。そういう意味では、前にも少し書きましたが、課題がfree-choiceであることが"value"のコードを議論するにあたってどうして重要なのか、というあたりを考えておく必要があると思います。じつのところ、Nature Review Neuroscienceの"CHOOSING THE GREATER OF TWO GOODS: NEURAL CURRENCIES FOR VALUATION AND DECISION MAKING." Leo P. Sugrue, Greg S. Corrado and William T. Newsomeがすでにこの問題を議論しています。その辺についてもメモっておきたいのですが、次回にでも。
- / ツイートする
- / 投稿日: 2005年12月08日
- / カテゴリー: [行動の価値 (action value)]
- / Edit(管理者用)
2005年12月07日
■ 「行動の価値」を表す線条体ニューロン
Science 11/25 "Representation of Action-Specific Reward Values in the Striatum"
ここまでは当たり障りのないことしか書いてこなかったので、もうちょっと論文に食い込んだことを語りましょう。論文のデータじたいに関するコメントです。
まず、行動のデータ、Fig.1についてですが、Fig.1Dとかを見ていると、Block内でどのくらい安定して選択をしているか、というあたりがまだ不十分なように見受けられます。同様な問題はGlimcher論文でもありました。Glimcher論文では、Nash平衡に到達しているときに成り立つ関係をデータの解釈に持ち込んでいるため、平衡状態が成り立っていないと論文のロジックそのものが崩壊する、という問題がありました。一方、今回の論文ではあくまで選択のバイアスさえ形成されればよいので、Glimcher論文ほどは深刻な問題になっていないのは確かです。しかし、あとあと問題になるであろうことは、50-10と90-50との間でそんなに差がないこと、つまり、左右のP(r)に偏りがあると行動選択が極端に片側に偏ってしまう、という点です。(後述しますが、行動選択率に極端な偏りがあるため、caudateニューロンのaction valueではなくてaction selectionによる効果が見えにくくなっているのではないか、というのがわたしが問題点に挙げたいところです。) 本当は80-50や50-20とかの方がよかったではないだろうか、と思います。
それからやっぱり、ニューロンのデータが食い足りないと思うのですな。Fig.1でブロックごとの行動のデータが出てますが、これにはニューロンのデータが付くべきだと思うのです。たとえば、Glimcher論文のFig.6Aとか。彦坂グループのNature論文のFig.2aとか。Blockの切り替わりによってどのくらいニューロンの発火が切り替わってゆくか、というspecimenのデータがないことで、この論文のニューロンのデータの印象が弱くなっていると思うのです。
Fig.3に関して。Q_RとQ_Lとそれぞれのslopeの有意度の分布ですが、なんらかのdistinctなpopulationがあるというよりは、まんべんなく広がっているように見えます。もしくは率直に言えば、左上から右下に向けて分布している(V,-Vの部分がないわけだから)ように見えます。このことは、delta-Q、つまり行動選択が左か右かをコードしている、という軸(このscattteredでy=-xのライン)に沿って広がっているということであり、Q_RやQ_Lを単独でコードしているニューロンもこの分布の中からたまたま出てきた、というふうにも見えます(意地悪く言えば、ですが)。T-valueではなくて、slopeそのもので見たらばまた印象は変わってくるかもしれませんが。
んでもってわたしがデータの面でいちばん問題だと思っているのは以下の点です。Fig.3BでのQ_R type、Q_L type、m typeという分類の仕方についてはsupplementary dataのほうに手続きが書いてありますが、まず、ニューロンの発火をQ_RとQ_Lとのモデルでregressionしたあとで、その残差をactionやreaction timeでregressしています(supplementary data p.4中段)。これはまったくフェアではありません。このモデルはそのあとで出てくるFig.4で使った、Q_RとQ_L、actionやreaction timeを全部同時につっこんだモデルと等価ではありません。本当ならactionで有意になるかもしれなかったニューロンで、Q_RまたはQ_Lのfactorの有意度としてsum of squareが差し引かれてしまっている可能性があります。問題は、Q_Rが高いときにはactionがRになる確率が高いということで、二つの独立変数(この場合Q_Rとa)の相関係数が高いときにその両者を使って従属変数のニューロンの発火頻度をregressしようとするとregressionは不正確もしくは不安定になります。いわゆるmulticollinearityの問題です。また、前述の通り、行動選択率に極端な偏りがあるため、それぞれのブロックでのactionのデータ数にも極端な偏りがあります。たとえば、[90-50 / 50-90] * [a=left / a=right]のマトリックスを作ってやると、おそらくデータ数nは[9:1:1:9]のような偏りができているはずです。このような状態では正確なfittingは難しくなりますし、そもそもinteractionを考えないとまずい場面です。SASなどではinteraction termの計算法にtype IIとtype IIIとがあり、どちらの立場を取るか(個々のニューロンのデータに等しい重みを付けるか、マトリックス間で重みを等しくするか)によって大きく結果が変わってくることがあるということも知られています。このパラグラフで指摘した点は、caudateニューロンがaction valueをコードしているのか、action selectionをコードしているのか、という検証に直接関わるので深刻な問題ではないか、これが私の意見です。とはいえ、以上のことがわたしの勘違いに基づいている可能性がありますので、もう少し考えてみようかと思います。次回につづきます。
一つ追加。違った言い方をするならば、delta-Q = actionであることと、Q_RやQ_Lとは独立にactionのtermをモデルに入れることあたりの問題にもなります。つまり、Firing rate = Q_R + Q_L + Q_R * Q_Lというモデルを考えるとinteraction termはaction selectionのことになるのです。著者はdelta-Qはaction selectionとも言える、というようなスタンスを取っているように見えますが、parsimonious性を考えるならば、「実際に取ったaction」で説明できるときは「左右のvalueの差」で説明することは断念しなければならないでしょうし。うーむ、前にもこういうシチュエーションあったな。実験デザインとしては要因Aと要因Bとのfactorial designなのだけれど、要因Aと要因Bのinteractionじたいが別の要因として捉えることが可能である、というもの。マトリックスにするなら、[A * B]で効果が[1,1;0,0]なら要因Aのmain effect、効果が[1,0;1,0]なら要因Bのmain effect、でも、[1,0;0,1]のときがあって、本当は要因Cを考えるのがいちばん良かった、という場合の要因A、B、Cの関係の問題ってやつ。
さらに追加。上のパラグラフ、正確でないですな。delta-Qは定義上(Fig.3Aでのsacattered plot上で分類しているものと思われます)、Q_RとQ_Lと両方の要因が有意でかつeffectの向きが逆のものだから、上の様式でeffect sizeを書くならば、[1,0;0,-1]のようなものになり、かならずしもinteractionがあるとは限らない。もう少し考えてみます。
- / ツイートする
- / 投稿日: 2005年12月07日
- / カテゴリー: [行動の価値 (action value)]
- / Edit(管理者用)
2005年12月05日
■ 「行動の価値」を表す線条体ニューロン
Science 11/25 "Representation of Action-Specific Reward Values in the Striatum"
今回は予告編に基づき、この論文の意義に関して。とくに「価値」のニューロン表現に関するさいきんの研究をふまえて。また、「強化学習則」を大脳基底核にどう埋め込むか、という議論に関して。
まずこの論文の意義ですが、題名の通りで、striatumにおいて、rewardそのものでもなければ、actionそのものでもなくて、valueをコードしているところを見つけた、ということになります。かといって、NewsomeやGlimcherがLIPで見出した「いくつかの選択肢のrelative valueをコードするニューロン」というのとも違います(注1)。というのも、LIPのニューロンの場合、それは「相対的な」価値をコードしていて、左右の選択のどちらが価値が高いか、を実際の行動選択率とは独立した形でコードしている、と主張するものでした。いっぽうでstriatumのニューロンは、いわば「絶対的な」価値です。左の選択の価値が高いかどうかを右の選択の価値とは独立してコードしているのですから。
最終パラグラフにあるように、striatumはSNc/VTAのdopamineニューロンから直接入力を受ける領域であり、脳の中でreward valueをコードする最初の場所かもしれないわけです。著者らは明確な形では主張しておりませんが、このことはsriatumのabsolute valueをコードするニューロンがLIPなどでみられるrelative valueをコードするニューロンのより上流に位置することを示唆します。とはいえこれはわたしの勇み足で、著者らはこのあいだのEK MillerのNatureを引いておくだけにして、LIPに関しては全く言及しておりません。(上記の論文自体がreferされておりません。)
これまでの大脳基底核からの記録の論文との突き合わせ、という点からは彦坂先生の1DR-4DR taskでcaudateのニューロンからの記録した、という論文(Kawagoe et al '98とか)との関連が重要です。Kawagoe et al '98はreward x actionのinteractionをコードしていると言えると思いますが、free choice課題ではないため、行動のvalue、とは言えない、というところでしょうか。このへん要補足です。
もう一つの意義は、というかこちらが本当はメインなわけですが、大脳基底核で「強化学習則」がどのように埋め込まれているか、を解明した点にあります。端的に説明しましょう。
Shultzの仕事から、SNcなどのdopamineニューロンがTD error(報酬の予測のエラー。予想外に報酬が出たらプラス、予想外に報酬が出なかったらマイナス、予想通り報酬が出ればゼロ、予想通り報酬が出なければゼロ)をコードしていることはほぼ確立した、というかここ最近10年間のニューロサイエンスの大きな収穫の一つです。そのようなTD errorを使うことで「強化学習」を行うことが出来ます。「強化学習」とはなにか。いってみれば「ダメ出し学習法」です。見本は見せないで結果だけ判断。いいときは報酬、ダメなときはダメ。それだけ(注2)。環境と関わり合いながら行動して、そのつど与えられる報酬から適切な行動を選択してゆく、というのが強化学習で、そのときにどのような学習則を用いるのが最適であるか、というのがこの分野の問題です。
そのような学習則にはActor-critic仮説とQ-learning仮説があります。大脳基底核でこの強化学習がどのように埋め込まれているか、という問題に関しては、Sutton and Barto(「強化学習」の教科書の著者)はActor-critic仮説に基づいて、SNc/VTAからのTD errorのシグナルが直接、選択されるべき行動をmodulateします。いっぽうで、Doya説ではQ-learning仮説に基づいて、SNc/VTAからのTD errorのシグナルはいくつかの行動選択肢が持っているvalue(action value)をmodulateし、それが下流での選択されるべき行動のcompetitionに影響を与える、というモデルになっています。
よって今回の論文のロジックはこういうことになります:もし、大脳基底核にaction valueをコードしている部分があれば、action valueをコードするモジュールを想定していないSutton and Barto説は否定される。つまり、「action valueをコードしている領域がどこかにある」ということさえ言えれば十分であるというわけで、それを示したのが今回の論文の意義だ、というわけです。だから、Sutton and Barto説でもaction valueがコードされるモジュールを取り込めばrejectされた、とまで言われる筋合いはないとも言えます、もっとも、それがactor-criticなのかどうかはよくわからないのですが。
ああ、また知らんことをわかったように言ってしまいました。ツッコんでください。ではまた次回。
(注1: なお、LIPでのニューロンに関しては、これまでうちのサイトで言及してきたNewsomeグループの選択行動に関するScience '04(議論スレッドへのリンク)やGlimcherグループによるナッシュ均衡に関するNeuron '04(議論スレッドへのリンク)などで詳しく議論されております。)
(注2: 著者の一人であるATRの銅谷さんはCurrent opinion in Neurobiology '00などで、大脳基底核は強化学習、小脳には教師ありの誤差学習、大脳には教師なし学習(刺激の統計的性質などの学習)、を行うメカニズムがを埋め込まれていることを主張しています。これは現在「数理科学」での連載でさらに展開されています。)
- / ツイートする
- / 投稿日: 2005年12月05日
- / カテゴリー: [行動の価値 (action value)]
- / Edit(管理者用)
お勧めエントリ
- 細胞外電極はなにを見ているか(1) 20080727 (2) リニューアル版 20081107
- 総説 長期記憶の脳内メカニズム 20100909
- 駒場講義2013 「意識の科学的研究 - 盲視を起点に」20130626
- 駒場講義2012レジメ 意識と注意の脳内メカニズム(1) 注意 20121010 (2) 意識 20121011
- 視覚、注意、言語で3*2の背側、腹側経路説 20140119
- 脳科学辞典の項目書いた 「盲視」 20130407
- 脳科学辞典の項目書いた 「気づき」 20130228
- 脳科学辞典の項目書いた 「サリエンシー」 20121224
- 脳科学辞典の項目書いた 「マイクロサッケード」 20121227
- 盲視でおこる「なにかあるかんじ」 20110126
- DKL色空間についてまとめ 20090113
- 科学基礎論学会 秋の研究例会 ワークショップ「意識の神経科学と神経現象学」レジメ 20131102
- ギャラガー&ザハヴィ『現象学的な心』合評会レジメ 20130628
- Marrのrepresentationとprocessをベイトソン流に解釈する (1) 20100317 (2) 20100317
- 半側空間無視と同名半盲とは区別できるか?(1) 20080220 (2) 半側空間無視の原因部位は? 20080221
- MarrのVisionの最初と最後だけを読む 20071213