[カテゴリー別保管庫] 生理研研究会2012「推論の脳内メカニズム」
2012年09月08日
■ 生理研研究会 予習シリーズ:ラットの因果推論と連合学習理論(5)
さて予習シリーズの最終回です。
長くなったので、第一回から最終回までつなげたPDFを作りました。ご利用ください:pdf (11MB)
[統計的因果推論]
前回の統計的因果推論の話をまとめると、もし因果モデルの知識を「観察」によって獲得しているならば、observe条件 (「介入なし」)とintervene条件(「介入あり」)とで、common-causeモデルの場合の下流のノード間の共変の程度を正確に予測できる。
ヒト心理学実験(Waldmann et al 2005)ではこれは成り立ち、赤ちゃんでも成り立つ(Gopnik et al 2004)。この論理でもってラットの因果推論を検証したのがScience 2006だった。
でも、ベイズネットのモデルの前提として、たとえばcommon-causeのモデルの場合、下流の二つのノードであるT(トーン)とF(砂糖水)では、P(T)とP(F)が独立でなくてはいけない。つまり、P(T, F) = P(T) * P(F) でないといけない。 ところがラットの実験ではすべての実験条件において、独立性の条件を満たしていない。
たとえば、Science 2006 exp1では、L->T, L->Fをinterleaveして与えている(前々回の記事を参照)。これだとP(T=1 | L=1)=0.5, P(F=1 | L=1)=0.5としたうえで、TとFとはけっして同時には出ない。つまり、
P(T=1, F=1) = 0 P(T=1) * P(F=1) = 1
となっていて、独立性の条件を満たしていない。それどころか、TとFは逆相関している。つまり、P(F=0 | T=1)=1。
つまり、もしラットが合理的に因果推測を行っているならば、observation条件ではここで想定しているモデルでの予測とは逆に、テスト試行でのTに対するnose poke (CR)は低くなるはずだ。なぜなら、Tが出た時はぜったいFは出ないのだから。
また、Science 2006 exp2a,2b および Leising et al 2008 ではトレーニング試行を二つに分けて、L->T を教えてからそのあとで L->F を与えて、それからtestを行っている。これを確率で表せば、exp1と同じことになる。つまり、因果ベイズネットという認知的モデルではこれらの実験のラットの行動をうまく説明できない。
[Minimal Rational Model]
以上の疑問を抱いてこの論文を読んだ後で、Penn and Povinelli 2007が同じことを指摘していることに気付いた。さらに関連論文を読み進めてゆくと、Waldmann et al 2008で著者は、ラットの結果がベイズネット理論よりもBuehner and Cheng (2005)の"single-effect learning" modelでよりよく説明できる、と主張している。つまり、ラットについてはベイズネット理論を引っ込めた。
"Single-effect learning" modelとはどんなものかというと、連合学習理論で使われるpower-PC theoryの延長上にある理論で、ラットはcommon-causeのモデル全体を持っているのではなくて、L->T, L->Fというべつべつのリンクのモデルを持っている。そしてラットは、observe条件とintervene条件とでL->Tという因果の強さの評価を変えている。これがScience 2006で見られたdiscounting effectであると。(この部分Waldmann et al 2008にアクセスできなかったので、Penn and Povinelli 2009に基づいて書いてる。)
これはけっきょく、わたしが第一回目のまとめのときに書いた以下のこととほぼ同じだろう。
(ラットは)「トーン(純音)が鳴る」を説明する因果モデルとして
- 「ライトが点灯する」->「トーン(純音)が鳴る」
- 「レバーを押す」->「トーン(純音)が鳴る」
のうち後者を選択した。ゆえに前者を選択した場合に起こる鼻をつっこむ行動が減った。つまり「トーン(純音)が鳴る」からその原因を推測した
けっきょくベイズネットまで持ってこなくても、連合学習理論そのものでは説明できないということは堅い結果なので、適切なレベルの主張にしたということのようだ。(Waldmann et al 2008ではminimal rational modelとタイトルに書いている。) つまるところ話が反転していて、ふたたび連合学習理論による説明に大きく依存したモデルとなったのだ。
そこで一つ考えたのだけれども、Science 2006 exp2a,b以降の実験では、トレーニング試行でまずL->Tのブロックがあってからその後でL->Fをやっている。これはsensory preconditioningと言われる処理だ。これは推測だけど、もし実験操作の順番を変えて、L->F を与えてから L->T を教えたとしたらたぶんまた違った結果が得られることだろう。(予想するに、chainとcommonとで差が付かなくなる)
そういう意味でも、たぶんこの実験パラダイムのラットの結果を説明するためには連合学習理論が必要なのだろう。
[ベイズネット救済の道は?]
とはいえ、ベイズネットを引っ込める必要があるのだろうか? まあ、このへんを進めてゆくのはおそらくはAaron Blaisdellのほうの仕事なんだろうと思うけど、まだベイズネットの方向でできる気はする。
前回も指摘したように、独立性の前提を満たすような実験デザインでやればいいんじゃないの?とまあこういう実験やったことのない人間としては思った。前回書いたように、トレーニング試行を L->TF (TとFが同時に出る)というふうにしてやれば、独立性の条件も満たされるわけだし。
この疑問をtwitterで書いたところ、澤さんからお返事をいただいた。
- 「なんでもっとかんたんにP(T|L)=1, P(F|L)=1とはできないんだろう? それがいちばんcommon cause modelを素直に表現した状態だと思うのだけれども…」(pooneil)
- 「… P(T|L)=1, P(F|L)=1にするとエサ提示がトーンを隠蔽してしまってLight-Toneの学習が不完全になると思われます…」(kosukesa)
- 「…もちろん実験条件としてあってもいいとは思いますが,結果の解釈がクリアになるわけではないと思われます…」(kosukesa)
なるほど、ではovershadowingしすぎないように条件を変えられないだろうか? たとえば、L->TF, L->T, L->F, Lの四条件をinterleaveしてやれば、P(F=1 | L=1) = 0.5, P(T=1 | L=1) = 0.5となり、独立性の条件も満たされる。(まあ、充分にトレーニングをするのが難しそうだが。)
あと、今回のようなdeterministicなものでなくして確率振ってもいいし(P(F | L)=1ではなくて0.5とか)。Waldmann 2005が確率的であったことを考えると、たぶんいろいろやった結果ラットでできる限界はdeterministicなバージョンまでだったんだろうと予測するけど。
まあこのへんはラットではなくてサルかもしれない。サルだとovertrainしたうえで、probe testではなくて繰り返し記録しないといけないのが難点だけど、「思考」「推論」に関わるニューロン活動記録する方向でこの実験パラダイムを活用できないだろうか? そんなことを考えた。
あと逆に、ベイズネットの方をなんらか拡張して、今回の条件のデータと整合性のあるようにできないだろうか。前回ちょろっと書いたけど、P(T)とP(F)が独立でないということは、common-causeのモデルではないってことなので、すべてのjoint probabilityから実験データを正しく反映した本当のグラフ構造を作ることができる。そのうえでgraph surgery (介入による因果グラフ構造の変化)をやればいいんではないだろうか。そのうえで、L->F, L->Tの順番の違いとかはを因果モデル形成の際の履歴の効果として取り込む。このくらいでなんとかならないだろうか。
赤ちゃんでできるのにラットでできないのはなんか認知能力の限界があるわけで、それは「因果推論のモジュールがあるかないか」みたいなブラックボックスでなくて、もっと記憶容量なり刺激般化能力なり、もっと具体的なものにできないだろうか。
[結論]
Science 2006の結果はこれまでの連合学習理論では説明できないような認知的な現象を見つけたということで、この部分に関しては非常に堅い。しかし、では因果推論に連合学習理論はいらないのかというとそういう話ではない。連合学習理論が持っている実験デザインと行動説明能力は強力なので、認知的な説明をするときにもそれらを入れていかないとトップダウン的で説明能力の低いものとなってしまうようだ。それが今回の一連の話の後半で出てきた話。
連合学習理論と認知的理論との関係はどうなのかということを知りたくて、その一例としてこの論文を読んだという側面もある。なるほど簡単にすっぱり割切れるわけではないことがよく分かった。
さてこのへんからが本当に議論をしたいところだ。神経科学が思考のようなアクティブな現象を解明するとしたら、擬人化を完全に排除した心理モデルを持つ必要があって、それはどのようなものだろうか、ということについて議論したい。生理研研究会だけではなく、その後ででも。
参加者の皆さんがこのブログを読んでこのへんの分野の前提を共有してくれたら深いところまで話できないかなと期待している。
というわけでScience 2006を読み込むのが目的だったのだけれども、かなり長い話となった。話は長いが、無駄ははしょって、でも必要な部分は省略せずに書いたつもり。
予習シリーズはこれで終了です。それでは岡崎で会いましょう。
長くなったので、第一回から最終回までつなげたPDFを作りました。ご利用ください:pdf (11MB)
[参考文献]
- Buehner, M. J. & Cheng, P. W. (2005). Causal Learning. In R. Morrison & K. J. Holyoak (Eds.) Handbook of Thinking and Reasoning. Cambridge University Press, pp143-168.
- Penn, D. & Povinelli, D.J. (2007). Causal cognition in human and nonhuman animals: A comparative, critical review.(pdf) Annual Review of Psychology, 58, 97-118.
- Penn, D. C. and D. J. Povinelli (2009). On Becoming Approximately Rational: The Relational Reinterpretation Hypothesis.(pdf) Rational Animals, Irrational Humans. S. Watanabe, A. P. Blaisdell and L. Huber. Tokyo, Keio University Press.
- Waldmann, M. R., Cheng, P. W., Hagmayer, Y., & Blaisdell, A. P. (2008). Causal learning in rats and humans: a minimal rational model. In N. Chater, & M. Oaksford (Eds.), The probabilistic mind. Prospects for Bayesian Cognitive Science (pp. 453-484). Oxford: University Press. (これはpdfはないが、google booksで部分的に読める。)
- / ツイートする
- / 投稿日: 2012年09月08日
- / カテゴリー: [生理研研究会2012「推論の脳内メカニズム」]
- / Edit(管理者用)
2012年09月07日
■ 生理研研究会 予習シリーズ:ラットの因果推論と連合学習理論(4)
さて、予習シリーズ前回の続き。今回は数式が多いけど、数式飛ばして日本語だけ読めば話は分かるはず。計算の方は簡単な条件を選んで、なるたけ計算手順省略しないで書いた。
(9/8追記:第一回から最終回までつなげたPDFを作りました。ご利用ください:pdf (11MB))
前回はScience 2006について、実験手順を詳しく追っていって、連合学習理論だけでは説明できない、因果推論に基づいた行動をラットがしているということを確認しました。
そのような行動は認知的理論である、ベイズネットによって説明できる、というわけですが、Science 2006の著者のWaldmann (ゲッティンゲン大学)がまさにこの論文にある実験系をヒトでのcausal knowledgeの研究に使ってきた人でした。
[統計的因果推論・観察・介入]
統計学の世界には「統計的因果推論」という分野がある。ここはまた深い世界だしわたしもよくわかってないので、ここで必要なことだけ書きます。
まずわれわれが「観察」で見ているのは相関であって、因果ではない。そこで「介入」をして何が起こったかを調べる。もしその介入がなかったらどうだったかという「反実仮想」をする。これは現実的には不可能だから、その代わりに介入をしなかった条件のグループを作る。(処置あり/なし * 介入あり/なし の2*2 で二マス分は欠損データになる。) でもって、[介入あり]-[介入なし]で因果関係を検出する、これが統計的因果推論。
このような操作をする際に「介入をする」という概念は統計学にはなかったので、それを「do演算子」というものを使って表現するようにしたのがJudea Pearl。do演算子に関しては後述する。Webで入手できる資料だとここに助けられた。
- 確率と因果を革命的に架橋する:Judea Pearlのdo演算子 ブログへのリンク
- 相関と因果について考える:統計的因果推論、その(不)可能性の中心 (Slideshare資料)
それで、Science 2006の著者のWaldmannはこのような統計的因果推論を、人間の因果推論をモデル化するために使った。ヒト心理実験によって、因果モデルの違い(common-causeかchain-causeか)によって「観察」と「介入」への効果が変わることを示した(Waldmann MR, Hagmayer Y. (2005))。つまり普通の人も、研究者みたいな因果推論をしているんだということ。
このような結果を基にして、それをラットに応用したのがScience 2006だった。
ここでは、ヒト実験(Waldmann MR, Hagmayer Y. (2005))の代わりに、肥満のたとえ話 (Hagmayer et.al., 2007) で説明してみる。
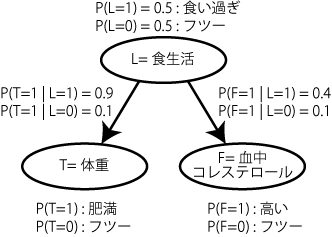
図のようにL,T,Fのcommon causeのモデルがあって、L,T,Fはそれぞれフツーかヤヴァイかの二通り。
ここでは、common-causeについてだけ説明する。まず、Common-causeでの確率は一般的な形で
P(L ,T, F) = P(T | L) * P(F | L) * P(L)
で計算できる。
Common-causeモデルでのobservation条件というのは、上記の一般的な式にT=1を入れたものになる。(Science 2006のテスト試行でトーンが鳴ったのと形式的に同じ。)
P(L, T=1, F) = P(T=1 | L) * P(F | L) * P(L)
一方で、intervention条件はどのように表記できるかというと、前述のPearlのdo演算子というのを使う。do(T=1)と書く。なにが違うかというと、
- 観察: P(L, T=1, F) --- データの中からT=1のものを選ぶ
- 介入: P(L, do(T=1), F) --- Tを1にセットする。
ということ。これは言葉遊びではなくて、実際の計算も変わる。というのも、P(do(T=1) | L) = 1 だから。(Lによらず、T=1にセットしたから。)
P(L, do(T=1), F) = P(do(T=1) | L) * P(F | L) * P(L) = P(F | L) * P(L)
つまり、intervene条件では、Tはこの因果グラフとは無関係になる。これはなるほど理にかなってる。
では、T=1を見た時にF=1であること(ある人が肥満だった場合に、その人の血中コレステロール量が高い確率)を推定してみよう。これはScience 2006のobservation条件で「Toneが鳴る」から「砂糖水が出る」を推測するのと形式的には同じ。
P(F=1 | T=1)
= P(F=1 | L=1) * P(L=1 | T=1) + P(F=1 | L=0) * P(L=0 | T=1)
= 0.4 * 0.9 + 0.1 * 0.1
= 0.37
P(L=1 | T=1)およびP(L=0 | T=1)はベイズの法則で計算する:
P(L=1 | T=1) = P(T=1 | L=1) * P(L=1) / { P(T=1 | L=1) * P(L=1) + P(T=1 | L=0) * P(L=0) }
P(L=0 | T=1) = P(T=1 | L=0) * P(L=0) / { P(T=1 | L=1) * P(L=1) + P(T=1 | L=0) * P(L=0) }
ではintervene条件で、T=1にセットしたときにF=1である確率を計算してみる。これはつまり重りでも持たせて体重計の目方を因果モデルとはべつのところから操作したときの血中コレステロール量が高い確率だ。
P(F=1 | do(T=1)) = P(F=1 | L=1) * P(L=1 |do(T=1)) + P(F=1 | L=0) * P(L=0 |do(T=1)) = P(F=1 | L=1) * P(L=1) + P(F=1 | L=0) * P(L=0) = 0.4 * 0.5 + 0.1 * 0.5 = 0.25
と計算できる。さっきのobservation条件での0.37よりも小さい値になっている、つまり、介入によって、P(F=1)の確率は変わった、つまりわれわれは介入によってFの推定を変えているし、そのことが介入がFを因果的に変えたことを認知している証拠となる。
[ラットの実験に当てはめてみる]
さて、このモデルをラットの実験に当てはめてみよう。じつは実験をデザインする際に、重要な前提条件がある。このようなcommon-causeのベイズネットでモデルするためには、P(T)とP(F)が独立でなくてはいけない。つまり、P(T, F) = P(T) * P(F) でないといけない。(これを違反すると、因果の矢がループしてしまう -- と思ったけど、その場合にはニセの因果を分離できるようなだがどうなんだ?)
一方で、Science 2006、JEPG 2008、IJCP 2009 のすべての実験条件において、L->TとL->Fとは常にべつべつの時間に起こるイベントだったため、独立性の条件を満たしていない。詳しいことは次回説明します。
今回は説明のために、この因果モデルが当てはまるような実験デザインだったとして、Science 2006のような結果が得られたらどのように説明できるか、について書きます。独立性の条件を満たそうとすると、トレーニングは L->TF、つまりライト点灯の後でトーンと砂糖水とが両方同時に提示される条件となります。つまり、
P(F=1 | L=1) = 1 P(T=1 | L=1) = 1 P(F=1, T=1 | L=1) = P(F=1 | L=1) * P(T=1 | L=1) = 1
ということ。
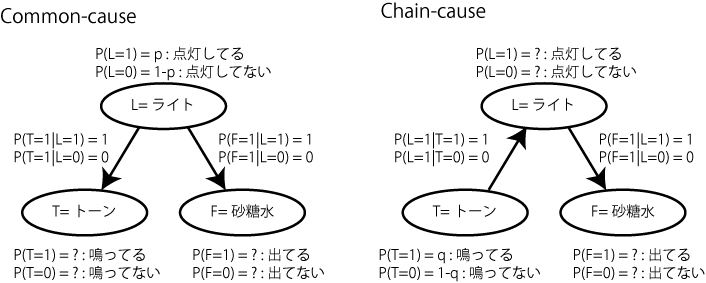
肥満の話との違いは完全に決定論的になっているということ。よって計算はもっとシンプルになる。これでCommon-causeでのobservation条件を計算すると、
P(F=1 | T=1) = P(F=1 | L=1) * P(L=1 | T=1) + P(F=1 | L=0) * P(L=0 | T=1) = 1 * 1 + 0 * 0 = 1
Intervene条件を計算すると、
P(F=1 | do(T=1)) = P(F=1 | L=1) * P(L=1 | do(T=1)) + P(F=1 | L=0) * P(L=0 | do(T=1)) = P(F=1 | L=1) * P(L=1) + P(F=1 | L=0) * P(L=0) = 1 * p + 0 * (1-p) = p < 1
となる。( P(L=x | do(T=1)) = P(L=x) より。あと、pはテスト期間全体のうちライトの付いている確率なので、1よりも小さい。)
よって、砂糖水が出ている確率を低いものと推測するのでnose poke(CR)が減る、というふうに説明できる。
ではchain-causeのときはどうなるか。まず、chain-causeのときの一般的な関係は、
P(L, T, F) = P(F | L) * P(L | T) * P(T)
Chain-causeでのObservation条件, intervene条件はそれぞれ
P(L, T=1, F) = P(F | L) * P(L | T=1) * P(T=1)
P(L, do(T=1), F) = P(F | L) * P(L | do(T=1)) * P(do(T=1)) = P(F | L) * P(L | T=1)
となる。( P(do(T=1))=1 および P(L | do(T=1)) = P(L | T=1) より。)
Chain-ObservationでF=1(砂糖水が出ているとき)を推測すると、
P(F=1 | T=1) = P(F=1 | L=1) * P(L=1 | T=1) + P(F=1 | L=0) * P(L=0 | T=1) = 1 * 1 + 0 * 0 = 1
となる。Chain-InterveneでF=1(砂糖水が出ているとき)を推測すると、
P(F=1 | do(T=1)) = P(F=1 | L=1) * P(L=1 | T=1) + P(F=1 | L=0) * P(L=0 | T=1) = 1 * 1 + 0 * 0 = 1
つまり、observation条件とintervene条件とは等しくなる。というわけで実験データを再現できた!
しかしこれは仮想的な実験デザインでの話でした。実際のラットの実験の話については次回。次が最終回。
[参考文献]
- Hagmayer, Y., Sloman, S. A., Lagnado, D. A., & Waldmann, M. R. (2007). Causal reasoning through intervention.(pdf) In A. Gopnik, & L. Schulz (Eds.), Causal learning: Psychology, philosophy, and computation (pp. 86-100). Oxford: Oxford University Press.
- Waldmann MR, Hagmayer Y. (2005) Seeing versus doing: two modes of accessing causal knowledge.(pdf) J Exp Psychol Learn Mem Cogn. 2005 Mar;31(2):216-27.
- / ツイートする
- / 投稿日: 2012年09月07日
- / カテゴリー: [生理研研究会2012「推論の脳内メカニズム」]
- / Edit(管理者用)
2012年09月06日
■ 生理研研究会 予習シリーズ:ラットの因果推論と連合学習理論(3)
さて、予習シリーズ前回の続きです。
(9/8追記:第一回から最終回までつなげたPDFを作りました。ご利用ください:pdf (11MB))
前回の連合学習理論とはどういうものか、というまとめを踏まえて、もう一度Science 2006について今度は実験手順を詳しく追いながら深掘りします。
[Science 2006 exp 1]
まず実験1ですが、前回使ったテーブルの形式でまとめます:
| グループ | トレーニング | テスト | 結果 |
|---|---|---|---|
| Intervene-Common | L->F L->T NF |
P->T | CR low |
| Observe-Common | T | CR high | |
| Intervene-Direct | P->N | CR medium | |
| Observe-Direct | N | CR medium |
前々回のラットの実験の説明を思い出しながら読んでみてください。メインの比較は上の2行です。
トレーニングでcommon-causeのモデルを教え込むために、すべてのグループで、ライト点灯(L)したあとでトーンが鳴る(T)、ライト点灯(L)したあとで砂糖水が出る(F)の二つを混ぜて提示します。テストのときに、いちばん上のグループ(Intervene-Common)では、ラットがレバープレス(P)をするとトーンが鳴る(T)ようになっています。
レバーはテストの前までは隠してある。なんでラットが自発的にレバー押すかはよく分からんが、とにかくあらかじめ強化しているわけではない。
上から2番目のグループ(Observe-Common)では、ラットはトーン(T)を聞くだけ。隣の実験箱にIntervene-Commonグループのラットがいて、そいつがレバーを引いた時にトーンが鳴るようにしてあるので、トーンの鳴る回数は揃ってる。
その結果、鼻を砂糖水の出るノズルに突っ込む回数(CR)はObserve-Commonの方が多かった、というわけです。でもって、これは連合学習理論からは説明できない。なぜなら、トレーニング時の条件はまったく同じだから、Tの連合強度は二つのグループで同じになる。
二つのグループの違いはテスト時に自分でレバーを引くかどうかの違いだけだから、レバーを引くことによって、学習したことをどのように利用するかが変わる、ここまでは確実に言える。
(認知的理論としてベイズネットで考える時を正しく反映した実験になっているか、これについては次回。今回はあくまで連合学習理論からは説明できない、というところを押さえる。)
この結果を批判的な目で見てまずすぐに思いつくのは、「レバー引くのが忙しくて鼻突っ込むの忘れてるんじゃない?」「レバーに注意が向いた結果鼻突っ込む回数が減ったんじゃん?」というものだ。このような問題は、下の2列のコントロール群(Direct-cause)の結果から排除できる。
じつはトレーニング時にはすべてのグループで、もう一つの条件としてDirect-cause (NF)の条件を与えてある。これはノイズ(N)が出るのと同時に砂糖水(F)が出るというもの。これによってふつうに古典的条件付けが起きる。
Direct-cause群の二つでは、テスト時にはTの代わりにNを使う。もし上記の「忙しい説」「注意説」が正しければこの二つの間でも差が出るはずだ。だがそうではなかった。よって上記の説は排除できる。
また、この結果はラットがNとTをちゃんとべつものとして捉えていることも示している。(=ラットが刺激TとNを般化してない。)
[Science 2006 exp 2a]
もう一つの実験では、前々回説明したCommon-causeとchain-causeの二つを比較して、chain-causeでのみこの現象(レバー押させるとCR減少)が起こることを示している。
| グループ | トレーニング1 | トレーニング2 | テスト | 結果 |
|---|---|---|---|---|
| Intervene-Common | L->T | L->F | P->T | CR low |
| Observe-Common | T | CR high | ||
| Intervene-Chain | T->L | P->T | CR medium | |
| Observe-Chain | T | CR medium |
上の二つのグループ(Common-cause群)はさっきのexp1と同じ。下の二つのグループではトレーニング1での順番がひっくり返っている。つまり、L->TだったのがT->Lへ。あとは全部同じ。よって、連合強度的に考えれば、Tの出てくる回数は同じなので、CommonとChainとで差はない。
だが、Chain-cause群では、レバーを押すかどうかによるCRの違いはなかった。Chain-cause群のふたつだけを説明するなら連合学習理論で足りる(Tの連合強度は二つの条件で同じ)けれども、それではCommon-cause群の差が説明できない。
[JEPG 2008 exp1]
上記実験でもうひとつ押さえておきたいのは、本当にテスト試行でレバーを自分で押したことが重要なのかということだ。そこでScience 2006 exp 2aの条件に加えて、exogenous cue条件というのを加えた。
| グループ | トレーニング1 | トレーニング2 | テスト | 結果 |
|---|---|---|---|---|
| Intervene | L->T | L->F | P->T | CR low |
| Observe | T | CR high | ||
| Exogenous cue | C->T | CR high |
この条件では、レバー(P)の代わりにそれまで出したことのない刺激C(クリック音)を出して、そのあとにT(トーン)が出てくる。結果はobserve条件と同じくらいのCRだった。Intervene群での「自分でレバーを動かした結果として」トーンが鳴ったことこそがCRの差を生み出すらしい。つまり、exogenous cue条件では、クリック音(C)はラットが自分で出したわけではないので、そのあとでトーン(T)が出た理由としてこれまでのcommon-causeモデルを捨てる必要はない、ということらしい。
(テスト試行を繰り返していると、あらたな因果モデルC->Tができて、common-causeモデルによるL->Tを破棄しそうな気はするが。)
[IJCP 2009 exp1,2]
ラットの行動を(擬人化して)説明するために、前々回こんな書き方をした:
もしラットがcommon cause因果モデルを理解しているなら、「トーン(純音)が鳴る」ときには(ライトが点灯するかどうかは見えないのだけれども、)「砂糖水が出る」と推論して砂糖水の出るところに鼻をつっこむだろう。
でもこれはいま考えると正確でない。Science 2006の実験では、exp1のメソッド部分を読む限り、テスト時にはライト(電球)を外していない。ということはラットは「ライトが点灯するかどうかは見えないのだけれども、トーンと砂糖水とは時間的に同時に出るもんだ」と推測したのではなくて、「ライト付いてないけど、トーンと砂糖水とは時間的に同時に出るもんだ」と推測して行動していることになる。そりゃ本当か?
Science 2006のメソッド部分をよくよく読んでみると、exp2a,2bではライト(電球)を外している。そこには、ライトを外しておかないとchain-cause条件でTに反応しなくなるから(つまりchain-causeでnose pokeの回数が低くなる)、と説明がある。これをこのIJCP 2009論文で検討している。
| グループ | トレーニング1 | トレーニング2 | テスト | ライト | 結果 |
|---|---|---|---|---|---|
| Paired-Absent | T->L T->N |
L->F | T | Absent | CR high |
| Unpaired-Absent | N | CR low | |||
| Paired-Present | T | Present | CR medium | ||
| Unpaired-Present | N | CR medium |
実験ではchain-causeしかやってない。知りたいのはcommon-causeの方なのだけれども。
メインの実験はテーブルのいちばん上で(Paired-Absent)、T(トーン)->L(ライト)とL(ライト)->F(砂糖水)をトレーニングでやってから、テストでTを提示してnose pokeの回数(CR)を数える。これはScience 2006のexp2aでのchain-causeでobserve条件に相当する。ラットはcausal-chainを理解しているので、Tの提示によってFを予期するのでCRが高い、と説明できる。
2番目のグループ(Unpaired-Absent)ではF(砂糖水)と連合させていないN(ノイズ)をテストで出す。これと比べていちばん上の条件(Paired-Absent)のCRが高いので、causal chainを推測した証拠となる。
この二つのグループをまんま同じで、ライトの条件だけ変えた(電球を外さずに、点灯しないままになっている)のがPresent条件。このときにはテストでTを出しても、CRはNを出した時と変わらない。つまり、T->L->Fというchainが切れたとラットが推測したらしい行動をしている。
そういうわけで、ラットは「ライトがあるけど点灯していない」ことと「ライトが取り外されて情報がない」こととを区別しているという証拠が得られた。いまの文脈ではこれはchain-causeをちゃんと理解していることの押さえとなる。
でも、もう一度書くけど、実験ではchain-causeしかやってない。知りたいのはcommon-causeの方だ。Science 2006ではExp1とexp2とではいくつか条件が違っているが、exp2のほうがobserve-interveneの差が大きい。電球外した効果もあるかもしれない。
IJCP 2009のイントロではcommon-causeについて言及している文があって、common-causeではライトの不在を思い出さなければならないけれども、chain-causeではライトの不在をperceiveしている。後者の方がライトの不在がより明瞭だろう、というのだけれども、ちとよく分からん。どっちでも思い出さないといけないと思うのだけれども。ディカッションは読んでないので、このへん掘り下げてあるのかもしれない。
[まとめ]
実験手順を詳細に追って批判的に論理の道筋を追ってみたが、ラットが連合学習理論をそのまま適用しただけでは説明できないような行動をしていることは確かなようだ。
Science 2006論文のロジックとしては、帰無仮説としての連合学習理論を棄却して、causal bayes netという認知的理論を採用する、という形式になっている。ではこの結果はcausal bayes netの理論と合致しているのだろうか? これが次回のメイントピックとなる。
- / ツイートする
- / 投稿日: 2012年09月06日
- / カテゴリー: [生理研研究会2012「推論の脳内メカニズム」]
- / Edit(管理者用)
2012年09月05日
■ 生理研研究会 予習シリーズ:ラットの因果推論と連合学習理論(2)
さて、予習シリーズ前回の続きです。連合学習理論とはどういうものか説明しようというわけですが、網羅的にやるのは無理なんで、ここではいまの文脈に沿って「連合学習では因果推論をどのように説明するか」という感じでコンパクトにまとめるという方針で。
(9/8追記:第一回から最終回までつなげたPDFを作りました。ご利用ください:pdf (11MB))
[古典的条件づけ]
まず超基本のパブロフの古典的条件づけ(レスポンデント条件づけ)ですが、イヌをベルを鳴らすとえさが出るようにトレーニングしたら、ベルを鳴らすだけで唾液が出るようになった、という話でした。
これをテーブルで表現するとこうなる:
| グループ | トレーニング | テスト | 結果 |
|---|---|---|---|
| テスト群 | B->F | B | CR high |
| コントロール群 | B F |
CR low |
(なお、実験デザインを日常言語で説明するとややこしいので、こういう表記に慣れておくと便利。連合学習の世界はこのへんがよく形式化されていて美しい。)
ベル(B)を提示してから餌(F)がでるのを矢印で表現。唾液の分泌量(CR=conditioned response)の大小でBが条件づけられたことを示すことができる。
この現象はむりやり認知的に説明しようとするならば、「ベルによって餌が出ると推論したことによって唾液が出た」と言えなくもない。でも、連合学習理論では「ベルBと餌Fとが時間的接近によって連合した」で説明が付くので、オッカムの剃刀もしくはモーガンの公準によって、認知的説明は排除される。(S-SかS-Rかの議論は省略。)
(なお、これは認知的メカニズムをまったく使っていないという証明ではない。じっさい、ヒトでの実験では、トレーニング試行と同じ内容を口頭でインストラクションするだけでCRが出るようになるって話がある(Cook and Harris 1937など)。)
コントロールどんな感じがいいかと考えてみたが、教科書には載ってなかった。自分で考えるとしたら、刺激は提示されているが、カップルしていないという状況か。ということで、BとFとが独立して出ている条件というのをコントロールに入れておいた。オリジナルの実験がどうかは知らないが、いまやるならこれが最適のはず。
[ブロッキング]
時間的接近だけで連合学習の強度が決まるわけではないということが「ブロッキング」という条件から分かる。
| グループ | トレーニング1 | トレーニング2 | テスト | 結果 |
|---|---|---|---|---|
| テスト群 | L->F | LT->F | T | CR low |
| コントロール群 | - | CR high |
たとえばラットで、コントロール群ではトレーニング2でL(ライトの点灯)とT(トーンが鳴る)を同時に提示したあとに砂糖水(F)が出る。テスト試行でTを出すと砂糖水のバルブに頭を突っ込む行動(CR)が見られる。テスト群ではそれに加えてトレーニング1でL(ライトの点灯)に提示したあとに砂糖水(F)が出る。そうするとTへの反応(CR)が減る。
たとえ話としては、エビと枝豆を食べて腹を下した人はエビを食わなくなる。でももしそのまえに枝豆を食べて腹を下した経験がある場合はエビはふつうに食うだろう、ということ。これは必ずしも合理的判断ではないことに注意。
この現象のポイントは、テストしているTはトレーニングの段階ではテスト群もグループ群もトレーニング2でしか提示していないのだから、「時間的接近」だけでは説明できないということ。
これを説明するためにRWモデルというのが考えられた。式は出さない。ポイントは、連合学習の強度が予測誤差によって更新されるということ。
ブロッキングでは、トレーニング1のときにLに対する連合学習が進んで、LはFを予測するようになる(=予測誤差が0に近くなる)。このあとでトレーニング2でLTを提示しても、LはもうFを予測するようになっているので、LTによってはもう連合学習の強度は変化しない。このようにRWモデルによって説明できる。
ブロッキングは古典的条件づけよりも高次な現象だが、それでも連合学習期論によって十分説明できるため、認知的な過程を要請しない。「予測誤差」を持つためには「予測」が必要だが、これは「現在の連合強度」そのものなので、それを現在の状態とを比較することさえできればよい。
[逆行ブロッキング]
トレーニング1とトレーニング2とをひっくり返しただけの「逆行ブロッキング」という条件を作ることができる。ヒトの場合にはブロッキングと同様な効果が見られる。
| グループ | トレーニング1 | トレーニング2 | テスト | 結果 |
|---|---|---|---|---|
| テスト群 | LT->F | L->F | T | CR low |
| コントロール群 | - | CR high |
しかしこの現象はRWモデルでは説明できない。なぜなら、トレーニング2ではLが提示されているだけなので、Tについての予測誤差が変わるわけではないから。
これを説明するためにコンパレーター仮説では、RWモデル(とその仲間)のようにテストの結果がトレーニング時の連合強度の変化によって決まるのではなくて、テスト時にそれを読み出す時にいまテストされているTの強度だけではなくて以前提示されたLの強度と比較する過程がある、として説明する。このアイデアはベイズ決定に通じるものがあり、かなり「認知」寄りのモデルであると思う。
RWモデル自体もトレーニング2では、Tが出ていないということが連合強度を下げる、というふうにモデルを改変することによってこ逆行ブロッキングの結果を説明できる(Van Hamme and Wasserman (1994))。このような改変は刺激のある(=1)なし(=0)としたときのpriorを0.5として置くような操作なので、これも一段階「認知」寄りになっていると考えられる。
(このような現象はretrospective reavulationという範疇に入るのだけれども、ratでこれをテーブルにあるような形式のまんま誘導しようとすると難しいらしい。Miller and Mature 1996みたいにsensory preconditioningとか入れる必要がある。このへん重要そうだが今回の話ではスキップ。)
[まとめ]
そんなこんなで、連合学習理論はその根本の「連合強度の更新」というアイデアを保存しながら、より複雑な現象を説明するためにどんどん理論を拡張している。このため、連合学習理論と認知的理論との境界はかなり曖昧になっているように私には思える。
今回読んでいるScience 2006では「連合学習理論では説明できないような現象を見つけたから、これは認知的な過程(因果推論)である」という論法を使っている。(帰無仮説としての連合学習理論。) だから当然、今回見た流れのように、「それ連合学習理論で説明できるよ、ただし理論を拡張すればだけど」ということは起こるのではないかと思う。
これはきっと、澤(2012)にあった、
次のような反論も人口に膾炙している。すなわち,「たった一つの“高次機能”を仮定することと,“百通りの連合経路”を仮定することはどちらが節約的で単純な説明であろうか?」という反論である。
という問題意識に繋がるだろう。
[参考文献]
- 澤 幸祐 (2007). 古典的条件づけ理論におけるabsent cueの処理 専大人文論集(専修大学文学部紀要), 80, 245-263.
- 澤 幸祐 (2012). 連合学習理論は擬鼠主義の産物か -表現論としての連合理論- 動物心理学研究
- 川合 伸幸・久保(川合)南海子 (2008) ヒトと動物の回顧的推論について Cognitive Studies, 15(3), 378-391
- Van Hamme, L.J. & Wasserman, E.A. (1994). Cue competition in causality judgements: The role of nonpresentation of compound stimulus elements. Learning and Motivation, 25, 127–151.
- Shanks, D. R. (2007). Associationism and cognition: Human contingency learning at 25. Q J Exp Psychol (Hove) 60(3), 291-309
- Shanks, D. R. (2010). Learning: From Association to Cognition. ANNU REV PSYCHOL 61, 273-301
- / ツイートする
- / 投稿日: 2012年09月05日
- / カテゴリー: [生理研研究会2012「推論の脳内メカニズム」]
- / Edit(管理者用)
2012年09月03日
■ 生理研研究会 予習シリーズ:ラットの因果推論と連合学習理論(1)
生理研研究会「認知神経科学の先端 推論の脳内メカニズム」参加登録受付中です。
若手運営手伝い(旅費援助付き)のほうは締め切りを過ぎましたので受け付けを終了しました。合計でちょうど10名となりましたので、抽選は行わず、申し込みいただいた方全員採用となりました。お申し込みありがとうございました。
さて、生理研研究会 予習シリーズ、前回の続きです。講演者の澤 幸祐さんの仕事の紹介を兼ねながら、動物で「因果推論」の証拠を得るためにはどのような手続きが必要か、連合学習理論とはどういうものか、といったことをまとめておきたいと思います。
(9/8追記:第一回から最終回までつなげたPDFを作りました。ご利用ください:pdf (11MB))
今回メインで読むのは澤さんがUCLAに居られた時の仕事のうちのひとつで、「ラットが因果推論をする」というものです。
- Blaisdell AP, Sawa K, Leising KJ, Waldmann MR. (2006) Causal reasoning in rats.(pdf) Science. 311(5763):1020-2.
さらに補足的にこの論文の続編的な二つの論文にも言及します。
- Leising KJ, Wong J, Waldmann MR, Blaisdell AP. (2008) The special status of actions in causal reasoning in rats.(pdf) J Exp Psychol Gen. 137(3):514-27.
- Blaisdell, A. P., Leising, K. J., Stahlman, W. D., & Waldmann, M. S. (2009). Rats distinguish between absence of events and lack of information in sensory preconditioning.(pdf) International Journal of Comparative Psychology, 22, 1-18.
Science 2006では「ラットが因果推論をする」ということを見つけました。「因果推論をする」ってことを証明するにはどうすればよいか。この論文のNews and ViewsをClayton and Dickinsonが書いてますので、そこにある例を引いてみます。
- Clayton N, Dickinson A. (2006) Rational rats. Nat Neurosci.9(4):472-4.
つまり、「あなたは裏庭に洗濯物を干しました。居間に戻ってきてしばらくしたところで、表門側の窓に水滴が付いていることに気付きました。あなたは雨が降り始めたなと推測して、あわてて洗濯物を取り込みに行きます。
いっぽうで、もしあなたが洗濯物を干した後で、表門側の庭の芝生でスプリンクラーのスイッチを入れていたとしたら、表門側の窓に付いた水滴はスプリンクラーによるものだと判断するので、洗濯物を取り込みに行こうとは思わないでしょう。」
このたとえ話の前半部分の行動は以下のような因果モデルに基づいています。
- 「雨が降る」->「表門の窓に水滴が付く」
- 「雨が降る」->「洗濯物が濡れる」(->「洗濯物を取り込む」という行動を引き起こす)
さらに後者では
- (自分が)「スプリンクラーを起動した」->「表門の窓に水滴が付く」
という知識を元にして、「表門の窓に水滴が付く」を説明する因果モデルとして
- 「雨が降る」->「表門の窓に水滴が付く」
- (自分が)「スプリンクラーを起動した」->「表門の窓に水滴が付く」
のうち後者を選択した、つまり「表門の窓に水滴が付く」からその原因を推測したわけです。
というわけで、スプリンクラーを起動したかどうかの違いで洗濯物を取り込むかどうか行動が変わることが「因果推論」をしたことの証拠となるわけです。
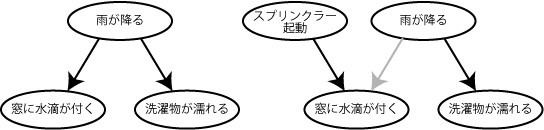
確率表現にするならば、これはベイズネットで表現できて、洗濯物を取り込みに行くかどうかは以下の確率に基づいて行動選択することになるでしょう。
- P(洗濯物が濡れる|表門の窓に水滴あり, スプリンクラー起動してない)
- P(洗濯物が濡れる|表門の窓に水滴あり, スプリンクラー起動した)
いったん脇道にそれますが、ポイントとしては、人は今示したようなcommon causeの因果モデルから因果の向きをひとつ逆向きにしたchain modelの因果モデルとを混同しません。
Common cause
- 「雨が降る」->「表門の窓に水滴が付く」
- 「雨が降る」->「洗濯物が濡れる」(->「洗濯物を取り込む」という行動を引き起こす)
Chain cause
- 「表門の窓に水滴が付く」->「雨が降る」
- 「雨が降る」->「洗濯物が濡れる」(->「洗濯物を取り込む」という行動を引き起こす)
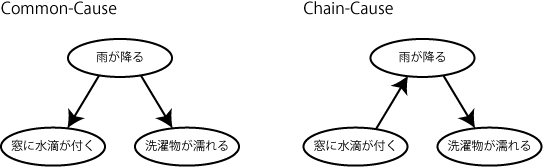
もしchain causeを信じていたら、スプリンクラーを起動するたびに洗濯物を取りに行くことになります。これは不合理。
- 「スプリンクラー起動する」-> 「表門の窓に水滴が付く」->「雨が降る」->「洗濯物が濡れる」
不合理だけど、そんな論理的誤謬のケースを考えてみた。
- 「夏休みが終わる」->「カレンダーが9/3になる」
- 「夏休みが終わる」->「宿題提出の期限が来る」
こういうcommon causeの因果モデルを我々は理解しているのだけれども、宿題提出の期限が来ないようにカレンダーの日付を一日戻す。
- 「カレンダーが9/3ではない」->「宿題提出の期限が来ない」
これは誤ってchain causeに基づいたという論理的誤謬なのだけど、その気持ちわかるなー。
もうひとつの例として「カーゴカルト」で当てはめてみた。(なお、これじたいの信憑性などについてはwikipediaへ。)
- 「アメリカ人がやってくる」->「飛行機がやってくる」
- 「アメリカ人がやってくる」->「食べ物が投下される」
こういうcommon causeの因果モデルがあるはずなのに、chain modelと誤解して、
- 「飛行機や軍服のパチものを作る」->「食べ物が投下される」
と理解できるわけ。こうしてみるとじつのところどのくらい非合理化だと言えるだろう?
話を戻すと、これと同等のものをラット用にデザインしてやれば、因果推測のテストとなるわけです。そこでScience 2006で使ったのは以下の条件です。
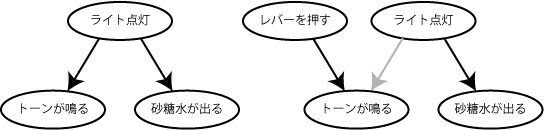
- 「ライトが点灯する」->「砂糖水が出る」
- 「ライトが点灯する」->「トーン(純音)が鳴る」
こういうcommon cause因果モデルを学習させる。テスト段階では、
- 「トーン(純音)が鳴る」
もしラットがcommon cause因果モデルを理解しているなら、「トーン(純音)が鳴る」ときには(ライトが点灯するかどうかは見えないのだけれども、)「砂糖水が出る」と推論して砂糖水の出るところに鼻をつっこむだろう。実際そうだった。
(なお、テスト条件では砂糖水は出ない。もし砂糖水が出てしまうとそれだけで強化されてしまうので、そのまえに学習したことのテストにならない。これはこの種の実験での基本的な手続き。)
テスト段階にはもう一つの条件があって、レバーを押したときだけトーン(純音)が鳴る。
- 「レバーを押す」->「トーン(純音)が鳴る」
ではこの条件のときにラットは砂糖水の出るところに鼻をつっこむかというと、さっきの条件よりも減った。
これはどういうことかというと、洗濯物の話のときと同じ。「トーン(純音)が鳴る」を説明する因果モデルとして
- 「ライトが点灯する」->「トーン(純音)が鳴る」
- 「レバーを押す」->「トーン(純音)が鳴る」
のうち後者を選択した。ゆえに前者を選択した場合に起こる鼻をつっこむ行動が減った。つまり「トーン(純音)が鳴る」からその原因を推測したわけです。
というわけで、レバーを押したかどうかの違いで鼻をつっこむ回数が変わることが「因果推論」をしたことの証拠となるわけです。なるほどね!
でも思うに、どうしてこんなに複雑な条件を使わないと「因果推論」を証明することが出来ないんだろう? われわれはもっとシンプルな条件でも因果推論をしていると思うのだけれども。
なんでかというと、もっとシンプルな条件のものは連合学習理論で充分説明できるからです。連合学習理論ではこれまでに説明したような「因果モデルを元に推論する」というような認知的なプロセスを仮定する必要がありません。
では連合学習理論とはどういうものか、これについては次回まとめてみます。
- / ツイートする
- / 投稿日: 2012年09月03日
- / カテゴリー: [生理研研究会2012「推論の脳内メカニズム」]
- / Edit(管理者用)
2012年08月19日
■ 生理研研究会 予習シリーズ1:講演者の紹介
生理研研究会「認知神経科学の先端 推論の脳内メカニズム」参加登録始まってます。若手運営手伝い(with旅費援助)は8/31締め切り。
さて、講演者の紹介を兼ねて、予習用の資料を用意してみようと思います。これまでの生理研研究会でもこんな感じのエントリを作成してきました。
- カテゴリー:生理研研究会2010「身体性の脳内メカニズム」
- カテゴリー:生理研研究会2009「意識の脳内メカニズム」
- カテゴリー:生理研研究会2008「動機づけと社会性の脳内メカニズム」
- カテゴリー:生理研研究会2007「注意と意志決定の脳内メカニズム」
これと同じ要領でまとめを作ってみることにしましょう。まだ今のところ、講演者の方からは要旨をいただく前ですので、講演内容については演題タイトルからの類推です。
1. 「眼球運動方向の自由選択における前頭連合野背外側部の役割」望月 圭 (京都大学大学院・人間環境学研究科)
望月さんは京大の船橋先生のラボの大学院生の方です。船橋研はいわずとしれた前頭連合野背外側部のニューロンのワーキングメモリーへの関与で有名ですが、今回は前頭連合野背外側部のニューロン活動が自由選択(free-choice)の条件と外からのキューがある条件とどう違うか、といった話になるようです。
今年のMotor Control 研究会でポスターを出しておられますので、おそらくはそれと同様な内容ではないかと思います。要旨:「眼球運動方向の自由選択における運動と選択の相反する履歴効果」
では「自由選択」を研究するのにはどういう意義があるか、これについてはご本人が研究の動機などを書いておられるので、ここを読んでもらった方が早いでしょう:Research Interests
2. 「リスク下の意思決定とモノアモン」高橋 英彦 (京都大学大学院・医学研究科)
高橋さんはsocial emotionの研究で有名です。
- Science 2009 "When Your Gain Is My Pain and Your Pain Is My Gain: Neural Correlates of Envy and Schadenfreude"
- PNAS2012 "Honesty mediates the relationship between serotonin and reaction to unfairness"
Science 2009のほうは「メシウマ状態」の脳基盤として話題になりましたし、PNAS2012もプレスリリースでは「夏目漱石の坊っちゃんのように、間違った事が大嫌いで義憤に駆られ、損ばかりする行動様式」と表現されて、人間の人間らしいところが題材となっていてスッゲー面白いです。
(fMRIと比べた場合の)PETの強みは神経伝達物質のイメージングができることなので、そちらをフルに活用した仕事をたくさん出しておられます。今回のトークのタイトルは
- Current Opinion in Neurobiology 2012 "Monoamines and assessment of risks"
と非常に近いので、おそらくは夏の包括脳シンポジウムでされていた、risk aversionの程度と線条体のドパミン(+NE, 5-HT)の関係の話になるのではないかと思います。
(Risk aversion: 効用曲線のslopeが損失のほうがよりsteepである - 1000円もらえるか1000円払うかの賭には人は参加しない。1000円もらえるか<1000円払うかならどっかで釣り合う。)
私自身としては、神経伝達物質のイメージングの話が銅谷さんの「メタ学習と神経修飾物質系」の話とどう繋がるかというところに興味があります。
3. 「意思決定の階層性と多重皮質-線条体ループ神経回路」鮫島 和行 (玉川大学・脳科学研究所)
鮫島さんは計算論的神経科学と神経生理学とを合体させて行動の価値を表象するニューロンを線条体で見つけた仕事
で有名です。以前ブログでもこの論文をとりあげてかなりこってりと読み込みました:カテゴリー:行動の価値 (action value)
さらにそのあとでは価値による意志決定を行動選択とは分離するような課題をデザインして、線条体の中でその分布を調べるというふうに仕事が展開してます。(未発表なのでOISTでのトークの要旨:The neural activities in the rostral-striatum during the cognitive decision-making)
今回の演題のタイトルからすると、「多重ループ」というのがキーワードとなりそうです。もともと鮫島さんは純粋に計算論の仕事でNeural Computation 2002 "Multiple model-based reinforcement learning"という、強化学習のモジュールを複数並べたもの(MOSAICの強化学習版)という仕事をされた方ですから。
4. 「因果推論・命題推論は連合学習理論で説明できるか」澤 幸祐 ( 専修大学 人間科学部 心理学科)
澤さんは連合学習理論の専門家です。個人的には今回の「推論」というテーマについて今回の講演者の方の中ではいちばん直接的に関わっている方だと思ってます。
わたしがお名前を知ったのは以下の二つの論文によってです。
- Science 2006 "Causal Reasoning in Rats"
- Nat Neurosci. 2008 "Reward prediction based on stimulus categorization in primate lateral prefrontal cortex"
連合学習理論については私自身の勉強が必要です。いまいろいろ調べてますので(「学習心理学における古典的条件づけの理論―パヴロフから連合学習研究の最先端まで」借りてきた)、別枠でエントリ作成します。
5. 「変化する環境への適応に関わるサル前頭前野外側部の神経活動」藤本 淳 (京都大学大学院・医学研究科)
藤本さんは京大河野ラボの小川研の大学院生の方です。昨年は夏の包括脳ネットワークで若手優秀発表賞を受賞されました。
注意と標的選択の仕事をされた小川さん(小川さんの仕事についてはブログでの紹介記事20070807をどうぞ)が京大に移られて新しく始めたプロジェクトが藤本さんがやっておられるこの仕事です。
行動の部分については論文になっています:Robotics and Autonomous Systems 2012 Dynamic alternation of primate response properties during trial-and-error knowledge updating
内容としては、WCSTみたいに、選ぶべきfeatureを決めるためのルールがブロックごとに変わっていて、ルールが変わった時にサルは必ずいったん間違えて、そこから試行錯誤でまたあたらしい答えを見つけていかないといけない。このときのニューロン活動を記録する。けっこう過酷。(双方ともに。)
6. 「さまざまな価値の認知的変容の神経基盤」松元 健二 (玉川大学・脳科学研究所)
松元さんはもともと霊長研->理研BSIでサル神経生理をやっておられました。2007年の研究会のときには松元さんがコレスポのNature Neurosci 2007の仕事について松元まどかさんにトークしていただきました。
- Nature Neuroscience 2007 "Medial prefrontal cell activity signaling prediction errors of action values"
- Science 2003 "Neuronal Correlates of Goal-Based Motor Selection in the Prefrontal Cortex"
また、2008年の生理研研究会のときには「動機づけと社会性の脳内メカニズム」というテーマで研究会をいっしょにオーガナイズしていただきました。
いまは動機づけと社会性のヒト神経機能イメージングの仕事を進めておられます。
- PNAS 2010 "Neural basis of the undermining effect of monetary reward on intrinsic motivation"
- PNAS 2010 "Neural correlates of cognitive dissonance and choice-induced preference change"
前者はアンダーマイニング効果、後者は認知的不協和、とそれぞれ心理学で知られていたけど脳基盤については分からなかったものを扱った非常に魅力的な仕事です。
7. 「部位特異的な中脳ドーパミンニューロンの活動とその機能的役割」松本 正幸 (京都大学・霊長類研究所)
松本さんは生理研の小松研でV1の仕事をされてから、NIHの彦坂先生のところでbasal gangliaについて以下の仕事を出されています。
- Nature 2009 "Two types of dopamine neuron distinctly convey positive and negative motivational signals"
- Nature 2007 "Lateral habenula as a source of negative reward signals in dopamine neurons"
神経生理学者ならみんなラボのJCで読んだことがあるはず。どっちも重要なんだけど、Nature 2009のほうが今回の話に近いでしょうか。
つまり、古典的条件付けの仕事で、aversiveなUS(air puff)を使った条件を入れてやると、中脳ドパミンニューロンの活動はSchultzとかが言ってきたようなprediction errorだけではなくて、appetitiveでもaversiveでも活動が上がるようなものが見つかってきた。 ニューロンの記録の位置から推定すると、air puffで活動が上がるものはSNcで、下がるものはVTA。
ご本人のサイトにある研究概要からすると、神経路選択的遺伝子導入手法を使っておられるそうですので、そのへんの話まで聞けるかどうか期待です。
8. 「情報選択と行動選択における前頭葉の役割:認知神経心理学からのアプローチ」熊田 孝恒 (理研BSI-トヨタ連携センター・認知行動科学連携ユニット)
熊田さんには2007年の生理研研究会のときにトークをしていただいて、今回が二回目となります。前回は「注意のトップダウン制御原理 - 次元加重、課題構え、探索モード」ということでお話しいただきましたが、今回は「認知神経心理学」ということで、前頭葉脳損傷の患者さんの話などになるのではないかと思います。
そのような方面からの仕事としては以下の論文があります。
- Cogn Neuropsychol. 2009 "Disinhibition of sequential actions following right frontal lobe damage"
- Cogn Neuropsychol. 2006 "Deficits in feature-based control of attention in a patient with a right fronto-temporal lesion"
以上です。ぜひぜひ研究会、いらしてください。
- / ツイートする
- / 投稿日: 2012年08月19日
- / カテゴリー: [生理研研究会2012「推論の脳内メカニズム」]
- / Edit(管理者用)
2012年08月08日
■ ところで「推論」ってなんですかね?
生理研研究会「認知神経科学の先端 推論の脳内メカニズム」 参加登録始まってます。
さて、それで今年のテーマは「推論の脳内メカニズム」なんですけど、「推論」ってなんですかね? いやいや、知らないで企画したわけではないんですが、話のとっかかりとしてですね。
今回共同オーガナイザーをしていただいている京都大学大学院・医学研究科の小川正さんに「研究会の狙い」と題して文章を書いていただいたのですが、それを引用すると、
実世界においてヒトや動物はさまざまな問題に直面するが、脳は柔軟に対処することによって問題の解決を試みる。そのような場合、環境や脳内に存在するさまざまな情報から必要とされる情報を能動的に選択・統合することによって問題解決に連なる行動に結び付ける過程(推論)が存在すると予想される。
というわけで、いまここでは「推論」としてそんな能動的な過程のことを考えています。はじめはタイトルを「思考・推論」としようとしたくらいで、まあ、そういったものをどう扱えばいいのかってのは、認知科学的に、もしくは工学的に知覚や運動制御を捉えたりするのとは違った難しさがあるわけです。
だからこそ小川さんは
現状において「推論」は少し先走った研究テーマではあるが、脳が有する高度な知的能力の解明に繋がる魅力的な研究対象である。
と書いたわけでしょうね。
今回お話しいただく方々はそれぞれご自身の問題意識があるので、だれもが「推論」とはなにかということそのものを直接問うているというわけではないのですが、このようなテーマの元で講演者の方々にお話しいただき、みんなで議論することによって、参加者の皆様の今後のあらたな問題設定とかに寄与できるんではないかと期待しております。
「推論とはなんぞや」ですが、上記の能動的vs受動的みたいな議論に入る必要は必ずしもないのかもしれません。そもそも我々に自由意志はあるのでしょうか?っていう話。
そうではなくて、bayesian inferenceでやってることとかを思い起こしてもらうならば、意志決定の過程で単純に二つの選択肢のエビデンスなり価値を比較するってあたりから、さらに複雑な要因を組み合わせた上で意志決定をするとすれば、それは推論の研究であると言えるでしょう。そういう意味では今回のテーマは2007年の「意志決定」の続編という側面もあります。
続きはまたこんど。
参加登録は研究会webサイトまでどうぞ。
若手(学部生、大学院生、ポスドク)への運営手伝い(旅費等の支援あり)の申し込みは締め切り8/31。
- / ツイートする
- / 投稿日: 2012年08月08日
- / カテゴリー: [生理研研究会2012「推論の脳内メカニズム」]
- / Edit(管理者用)
2012年08月06日
■ 生理研研究会 「認知神経科学の先端 推論の脳内メカニズム」参加登録開始しました
恒例の生理研研究会「認知神経科学の先端」ですが、今年は「推論」をテーマにして行います。
生理研研究会「認知神経科学の先端」シリーズも今年で5回目となりました。この研究会は毎年、認知神経科学の分野でテーマを絞って、さまざまなアプローチで活躍されている方に講演をしていただいて、ディスカッション重視のスタイルで行ってきました。
これまでのテーマは、
- 2007年は「注意と意思決定」 (ブログでの紹介スレ)
- 2008年は「動機づけと社会性」 (ブログでの紹介スレ)
- 2009年は「意識」 (ブログでの紹介スレ)
- 2010年は「身体性」 (ブログでの紹介スレ)
でした。昨年2011年はASSC15(国際意識学会)があったのでお休み。
そして今年は「推論」をテーマとして華麗に復活。
今年の講演者は以下の通りです。(敬称略、あいうえお順)
- 熊田 孝恒 (理研BSI-トヨタ連携センター・認知行動科学連携ユニット) 「情報選択と行動選択における前頭葉の役割:認知神経心理学からのアプローチ」
- 鮫島 和行 (玉川大学・脳科学研究所) 「意思決定の階層性と多重皮質-線条体ループ神経回路」
- 澤 幸祐 ( 専修大学 人間科学部 心理学科) 「因果推論・命題推論は連合学習理論で説明できるか」
- 高橋 英彦 (京都大学大学院・医学研究科) 「リスク下の意思決定とモノアモン」
- 藤本 淳 (京都大学大学院・医学研究科) 「変化する環境への適応に関わるサル前頭前野外側部の神経活動」
- 松元 健二 (玉川大学・脳科学研究所) 「さまざまな価値の認知的変容の神経基盤」
- 松本 正幸 (京都大学・霊長類研究所) 「部位特異的な中脳ドーパミンニューロンの活動とその機能的役割」
- 望月 圭 (京都大学大学院・人間環境学研究科) 「眼球運動方向の自由選択における前頭連合野背外側部の役割」
電気生理、機能イメージング、動物心理、計算論的神経科学、心理物理といったさまざまなアプローチで活躍されている先生方にお集まりいただき、最近の研究成果を紹介していただきます。ぜひお誘い合わせの上、ご参加ください。
参加登録はすでに始まっています。ぜひ研究会webサイトまでどうぞ。
それから、今年も包括脳からサポートをいただいて、若手(学部生、大学院生、ポスドク)への運営手伝い(旅費等の支援あり)の申し込みを開始しております。締め切り8/31で、定員10名、参加者多数の場合は抽選です。前回は早い者勝ち制にしたらけっきょく埋まるまで3週間くらいかかりました。じつにMOTTAINAI! 旅費、宿泊費タダです。学部生の方が研究の世界を知るのにもいい機会です。激しくオススメ。
講演者の紹介などについてはまた今度。
- / ツイートする
- / 投稿日: 2012年08月06日
- / カテゴリー: [生理研研究会2012「推論の脳内メカニズム」]
- / Edit(管理者用)
お勧めエントリ
- 細胞外電極はなにを見ているか(1) 20080727 (2) リニューアル版 20081107
- 総説 長期記憶の脳内メカニズム 20100909
- 駒場講義2013 「意識の科学的研究 - 盲視を起点に」20130626
- 駒場講義2012レジメ 意識と注意の脳内メカニズム(1) 注意 20121010 (2) 意識 20121011
- 視覚、注意、言語で3*2の背側、腹側経路説 20140119
- 脳科学辞典の項目書いた 「盲視」 20130407
- 脳科学辞典の項目書いた 「気づき」 20130228
- 脳科学辞典の項目書いた 「サリエンシー」 20121224
- 脳科学辞典の項目書いた 「マイクロサッケード」 20121227
- 盲視でおこる「なにかあるかんじ」 20110126
- DKL色空間についてまとめ 20090113
- 科学基礎論学会 秋の研究例会 ワークショップ「意識の神経科学と神経現象学」レジメ 20131102
- ギャラガー&ザハヴィ『現象学的な心』合評会レジメ 20130628
- Marrのrepresentationとprocessをベイトソン流に解釈する (1) 20100317 (2) 20100317
- 半側空間無視と同名半盲とは区別できるか?(1) 20080220 (2) 半側空間無視の原因部位は? 20080221
- MarrのVisionの最初と最後だけを読む 20071213