« EMアルゴリズムの勉強メモ | 最新のページに戻る | 「よくわかるフリストンの自由エネルギー原理」作成しました »
■ 最尤法、MAP法、ベイズ推定についてのまとめ
ずいぶんと昔の話なのだけど、「比率のデータにエラーバーを付けたいんだけど」っていう記事を作ったときに、最尤法でも尤度関数の分布を使ってエラーバー(ベイズ的なcredible interval)を付けることができるよね、というのをやったことがある。そのときどうもしっくりきてなかったことを整理してみる。
最尤法の具体例として(この例自体は今回の話に必須なわけではないが)、二項分布でコインの表裏を で表現するとして、n回のコイン投げデータ が確率モデル(二項分布)のパラメータ (コインの表が出る確率)の尤度関数 は
となる。最尤法ではこの尤度関数 の最大値となるパラメータ を推定する。
これはベイズの枠組みで言えば、無情報のprior を使って計算したposteriorの分布の最大値となるパラメータ を推定することと等価だ。
いっぽうでベイズ推定の場合には、尤度そのものを使うのではなくて、ベイズの定理からposteriorの分布を推定している。
もしここで点推定したければ、
となる。
こうしてみると、posteriorの分布を推論する(inference)ところと、そのあとパラメーター を点推定(estimate)するところを分けて整理できるなと思った。
さっそく作ってみた。
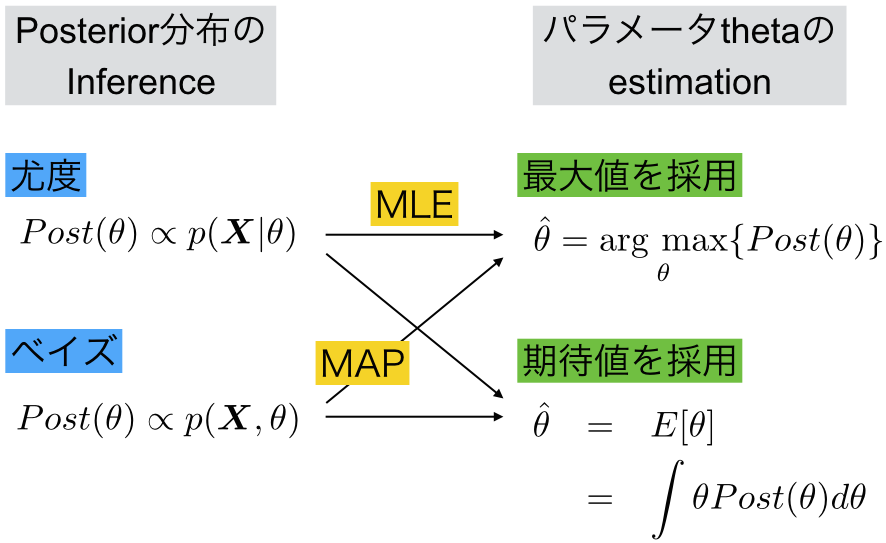
こんなかんじ。ベイズの定理に基づいてposteriorの分布を推論(infer)する方法に対して、priorの情報を使わない尤度を用いた方法がある。どちらもパラメーター の推測(estimate)を行う際には、最大値を採用する方法や期待値を採用する方法がある。
尤度関数の分布を求めた後に最大値を採用する方法が最大尤度法MLE(maximum likelihood estimation)であり、ベイズの公式でjoint probability (=generative model)の分布を求めた後に最大値を採用する方法がMAP法(maximum A posterior)だと。
つまり最大尤度法MLEという言葉を私が気持ち悪いなあと思ったのは、尤度関数を計算するところと、最大値を推定するところとが両方いっぺんに入っているからだということがわかった。「分布関数を計算する尤度推測(likelihood inference)」とそのあとの「最大値を採用する点推定MLE」みたいな言い方をするほうが混乱しなくていいんじゃないの?
なんか、MLEは点推定するけど、ベイズは点推定しないみたいな言い方はmisleadingだと思っていたので。
もちろんこれはベイズ史観であって、MLEを作ったフィッシャーの狙いとは異なるからこんな言い方はしないんだろうけど、そういった歴史的経緯以外にこの捉え方でまずいところってあるんだろうか?
でもってじつは本題は、このように整理すると、さらにhidden variable があるときのEMアルゴリズムと変分ベイズを並べることで2*2のマトリクスが作れるよって話だった。でもそこまで図を作る前に息切れしてしまった次第。
ところで、当たり前っちゃあ当たり前なんだけど、 も も も の関数であって、同じ一つのグラフの上に書ける。
それは当たり前のことなんだけど、式を字面だけ読んでいると、なんだか が の関数であるような(ぼんやりとした)勘違いをしてしることに気がついた。もちろん、べつに条件付き確率の左右にはどちらがgivenかといったそういう意味があるわけではない。