« この厳然たる事実を祝福しよう | 最新のページに戻る | そうして、このごろ1001 »
■ Amazonのカスタマーレビューの「有用性の高い順」ってどうやって決めてる?
Amazonで本を探したりするときにはレビューの文章をけっこう読んだりするのだけれども、あれは「このレビューが参考になった」の数に基づいた「有用性の高い順」でソートすることができる。そうするとしょうもないレビューを読まなくてすむ。まさにwisdom of clouds。
ところであの「有用性の高い順」ってどうやって決めてるんだろう? たとえばUSアマゾンのSlaughterhouse 5のレビューで、Most Helpful Firstでソートしてみると、一位が257/286 (全投票数286のうち、helpfulが257)で、次が212/236、67/75, 16/16, 28/31, という順番になっている。
一番のものから順番に、「helpfulに投票された比率」をプロットしてゆくと図のいちばん上のようになる。もしこの比率だけで並べられているならこんなにはデコボコにならない。
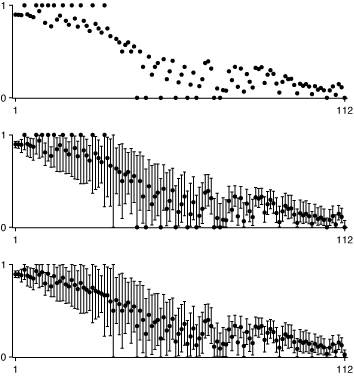
どうやら、「helpfulに投票された比率」だけではなくて、投票数も加味して順位を決めているっぽい。そりゃそうだよね。16/16と1/1ではデータの信頼度がぜんぜん違う。
そこで以前のエントリ(20090319)で作ったように、最尤法で95% credible intervalを計算してやって、エラーバーを付けてやったのが真ん中の図。それっぽくなってきた。ちなみにエラーバーが0-1になっているデータは0/0のもの。
「helpfulに投票された比率」は二項分布での最尤推定値だけど、そのかわりに尤度の分布で重み付き平均を計算して表示したのが下の図。(これをnon-informative priorでのベイズと捉えれば、前者がMAP推定に相当して、後者がベイズ推定に相当する。)
完全には同じでないのでなんかまだ違うことやっているようだけど、だいたい近づいたので満足した。
データ入りのmatlabスクリプトあり:sh5plot3.m ご自由にどうぞ。
…とここまで書いて、Amazonランキングの謎を解くという本があることを思い出した。関係あるんだろうか。まあいいや。(あとで図書館で見つけたが、売り上げランキングの話で、今回の話題とは関係なかった。)
余談だけど、順位が下のレビュー(helpfulの比率が10%以下)ってのはたいがいは読んでなくても書けるような文章、たとえば「退屈で難解、読む価値無し」みたいなやつだったりして、0/10とか付いても当然ってかんじでつまらん。でもたまにトラルファマドール星人に拉致られたとしか思えないようなものが見つかる。しかもレビューへのコメント欄が煽り合戦。まさに「いったい何と戦っているんだ」状態。