« 大泉匡史さん「意識の統合情報理論」セミナーまとめ(3/5) | 最新のページに戻る | 大泉匡史さん「意識の統合情報理論」セミナーまとめ(5/5) »
■ 大泉匡史さん「意識の統合情報理論」セミナーまとめ(4/5)
前回のつづき。(全5回分の記事をつなげてPDF化しました。まとめて読むときはこちらを使うことをお勧めします:IIT20161115.pdf)
3. IIT3.0での統合情報量φ
ここまで書いたのはIIT2.0での説明だった。一日目part3の説明はここからIIT3.0論文に準拠した説明になる。
3-1. Causeとeffectの考慮
IIT3.0がIIT2.0から進歩した点は、現在のニューロンネットワークが過去(入力)のネットワークとどのような因果ネットワークを形成しているかを表現したcause repertoireだけでなく、未来(出力)のネットワークとどのような因果ネットワークを形成しているかを表現したeffect repertoireも考慮するようになった点にある。
具体的には、cause repertoireを計算したのと同じようにeffect repertoireを計算して(ベイズの公式の使い方が変わるのでまったく同じ挙動にはならない)、cause, effecctそれぞれでのMIPを独立に決めてやって計算したφのうち小さい方をφとする、という操作を行っている。
(吉田コメント) これが必要な理屈についてはIIT3.0論文のFig.7で記述されている。要は過去から今、今から未来、両方共でintegrateしていないとintegrateしていると言えないでしょ、ということで、これはまったくごもっともで良い方向だと思う。しかし、端的にこのふたつのφ(の候補)をべつべつに計算して小さい方を選ぶという操作はずいぶんと後付けなやり方だと思う。言い方をパクらしてもらえば、causeとeffectがぜんぜんintegrateしてない。
(吉田コメント) Causeとeffectの両方がnon-zeroのときのみφもnon-zeroになるということを満たしたいだけだったら、φ(cause) * φ(effect) だって構わないはずだ。そうしてない理由はφの次元がbitだからで、bit同士の掛け算するのはおかしいだろうと考えたことは推測できる。しかし後述するearth mover distanceはじつのところbitの次元ではなくて確率p=0-1の次元のものなので、その場合、掛け算にするのはそんなに悪くないはずだ。つまり、このあたりはどうにも取って付けたようなかんじで、いくらでも他の方法はありえて、理論として未完成なように思う。
3-2. 片方向のpartition
これまでのpartitionというのは、たとえば2要素ABからなるネットワークでAB間の因果ネットワークを切る際には、A<-BおよびA->Bの両方が同時に切られていた。これはsplit brainの症例を想定して脳のfiberを物理的に切るような可能性だけを考慮していたのだろう。しかしこの場合、単純なfeed-forward networkでもpartitionによって情報がロスするため、φがnon-zeroになるという事態になっていた。
IIT3.0においてはそこで片方向のpartitionということを考えるようになった。このことは考慮すべきpartitionの数をさらに増やすというデメリットはあるものの、単純なfeed-forward networkのφをゼロにできるという大きなメリットがある。それはどういうことかというと、たとえば2要素ABからなるネットワークでAB間の因果ネットワークがA->Bの片方向のみだった場合、つまり{A(t-1)->B(t), B(t-1)->A(t)}のうちでB(t-1)->A(t)は元々切れてる(無相関)のときに、MIPとしてB->Aを切ったときを考えることができて、このとき情報ロスはないのでφ=0となる。だからどんなに要素数の多いネットワークでも、ある段階にfeed-forwardのみの部分があればそこはφ=0になるのだ、ということが言えるようになる。
(吉田コメント) これもIIT2.0のときの批判を受けて、後付けで作ったルールなのだろうとは思ったけれども、理屈として片方向のpartitionを考えるというのは正しい方向だとは思った。しかしこうなると、partitionの定義自体が何に基づいているのかということが曖昧になってくるかもしれない。つまり、ABC(t-1)->ABC(t)をpartitionするのにこれまではAB(t-1)->C(t), C(t-1)->AB(t)のように排他的にpartitionしていたのだけれども、それに限る必要はあるのか?ってことにならないだろうか?
3-3. Earth movers distance (EMD)
IIT3.0ではKLDの代わりにEMDというのを使っている。これは、KLDでは確率密度分布の横軸の構造を考慮していないという問題への対策。つまり、cause repertoireというのはネットワークの状態ごとの確率密度分布なので、横軸は(たとえば2要素ABならば)AB = {00, 01, 10, 11}の4水準ある。しかしこの軸には近接度の違いがある。IIT3.0で採用しているのはハミング距離だが、00と01, 00と10は距離1だが、00と11は距離2となる。(00-01-11-10-00というループを考えればよい。) EMDではこの近接性を考慮して距離を計算している。
(吉田コメント) しかし思うに、この距離というのも一意に決まるわけではない。別案として思いつくのは、TPMを元に、t-1からtへ行くときにどう遷移するかから近接度を考える策もある。そのような統計的性質を持ち込むことの是非は考慮すべきだが、一意に決まるわけではないということは示せたのではないかと思う。
3-4. Concept
IIT3ではさらにconceptという概念を導入する(IIT2.0のときよりもintegrateした形で理論に組み込まれた、という言い方が正確か)。ABCという3要素のネットワークがあるときに、そのサブセットである{A,B,C,AB,AC,BC,ABC}を考える。たとえば現在のBCに対しての過去の{A,B,C,AB,AC,BC,ABC}でそれぞれのMIPを決めてやる(purview)と、それぞれについてφが計算できて、この7個のφのうちの最大のものをcore causeと呼ぶ。これを過去についても同様にやってやるとcore effectができる。
こうして現在のA(t)に対するcore cause (たとえばBC(t-1))およびcore effect(たとえばB(t+1))ができると、このcause-effectの対をconceptと呼ぶ。ConceptはABCに対しては複数ありうるけど、core causeが0になってしまうようなものは消えるので、conceptの数はネットワークの状態(IITではstate + mechanismという言い方をする)しだいで変わる。
3-5. Constellation, Qualia space
このようにしてできた複数のconceptをネットワークの状態を軸にした空間の上に配置したものをconstellationと呼び、この配置パターンが現在の状態での意識状態のクオリアに対応しているのだ、という議論をIITではしている。そして、これらのconceptがシステム(今の例だとABC)のMIPによってどれだけ情報をロスするかをEMDで評価して、それをconceptの個数分でcause, effect両方共で足し合わせてやったものとしてΦを定義している。
IIT2.0でのΦはどちらかというとIIT3.0でのφに近い。IIT3.0ではConstellationの考えまでを統合したものとしてシステムのΦを定義付けてやろうという意図から、このような複雑な定式化をしている。
(吉田コメント) 率直に言ってこの部分にはまったく承服できない。まず言うべきこととしてはここでのconceptというのは日常言語で言うconceptとはまったく関わりがないものだということだ。また、ここでのconceptの配置がqualiaであるというのも説得的でない。そうなる理由が足りない。
(吉田コメント) 意識経験の違いとは多次元空間の中での脳状態の違いである、というような考え方はチャーチランドの神経哲学でもコネクショニズムでの多次元の表象という点から似たような図が出ていた記憶があるが、それと比べると本質的な違いがあるようには思えない。けっきょくのところ脳状態(個々のニューロンのinstateneousな発火状態)を用いるのか、それとも直前、直後の脳状態まで含めて考えるのか、という違いでしかないと思う。
(吉田コメント) 好意的に捉えるのであれば、このようなconstellationを用いて意識経験のinvalianceを説明することができる(しかし神経発火の状態空間では説明できない)というようなことを示すことができるのならば、このような議論にも意味があるとは言えるだろう。つまり、赤の赤らしさは変わらないままに、赤の経験の強度を変化させることができたとして、このときにconstellationの構造は変わらないままにΦだけが変わる、ということが示せるなら良いのではないかということ。Haun et al bioRxiv 2016でのFig.3はそれを目指しているのだろうと推測するけれど、少なくとも、神経発火の状態空間では説明できないものがここにあるといいうことを示す必要はあるはず。
(吉田コメント) そしてこのconstellationの議論が納得いかない最大の理由は、意識のcontentの議論を回避した上でqualiaだけ議論しようという点に無理があるということ。IITでは内的な情報量を考慮することを徹底しているため、外界の刺激が何で、なにが表象されて、ということは理論の外にある。その事自体はIITを他の理論と峻別する非常に重要な点なのだと思うのだけど、それゆえにIITでは表象を扱うことができず、意識のcontentの議論を行うことができない。そのような状態で「クオリア」だけを取り出して扱おうというのは無理だろうと思う。同様にして、IITのaxiomであるcompositionalityについてもIITでは明示的な方法では定式化することができない。(IIT3.0論文のFig.22が関連している。)
(吉田コメント) IIT3.0論文を詳しく読んでみると、表象の問題に関してはDiscussionで"matching"という概念について言及している。つまり、外界の因果的構造を脳内の因果的ネットワークがmatchするように学習の結果作り上げるという話で、ここは大変重要な問題であり、IITでも課題であることは認識されているように思う。
4. IIT3.0から示唆されること
ここからはIIT3.0論文の理論構築がいったん済んだ後で、この理論から示唆されることについて、より複雑な(でも脳よりはずっと単純な)モデルを元にして議論している。
4-1. どの脳部位が意識に関与するか?
有名な、「なぜ小脳は意識には関わらないか」という部分。重要な点としては、片方向のpartitionを導入したことによって、片道の結合が入っているネットワークはΦ=0になった。よって、網膜からLGN、そして大脳へ行く経路において、LGNは大脳から投射が来ていて双方向性だけど、網膜からLGNは片方向性。よって網膜からLGNの経路を除いたときにΦは大きくなり、exclusion postulateにより、網膜は意識の外にあるという結論になる。
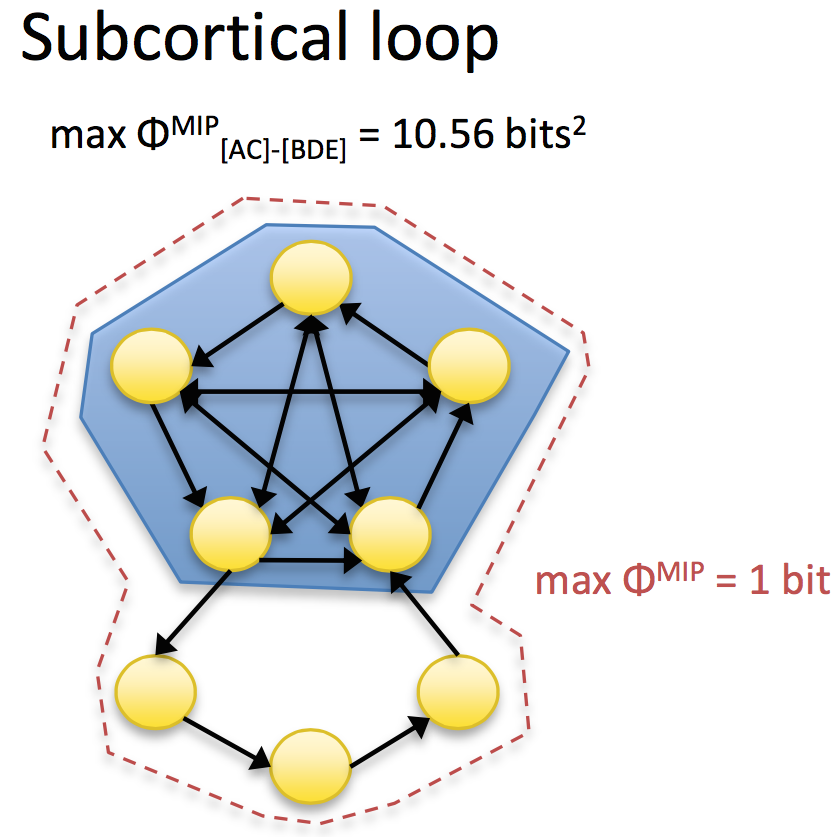
Figure 4 (大泉さん提供)
図4にIIT3.0でのsubcortical loop (basal gangliaを想定)を模したネットワークを示す。この図はBMC Neuroscience 2004のFig.4eと同じネットワークだが、IIT3.0の計算法を用いてΦを計算している(大泉さん提供)。Subcortical loopの部分を含めてΦを計算した場合(1 bit)と比べると、subcortical loopの部分を除くとより大きいΦになる(10.56 bit)ので、意識の境界としてはsubcortical loopは含まれない。
(吉田コメント) 私がここで注目するのはsubcortical loopの部分を含めてΦを計算すると値は低いがnon-zeroとなることだ。つまり、片道でもまたシステムに戻っていくループはIIT3.0でもΦがゼロにならない。このことはsensorimotor contingencyを考えるにあたって重要な点であると考えられる。因果ネットワークはニューロンでなくてもよいのだから、眼を動かすことによって視界が動いて視覚入力が変化するというのも因果ネットワークの一部として捉えることができるからだ。この件については次回の6-2で書く。いまの説明的に言及しておきたい点として、このループの何ステップなのかが因果の強さに関わってくること、そして統合の時間幅をどのくらいに取るかという問題に関わってくるということ。
4-2. “minimally conscious” photodiode
IIT3.0論文のFig.19の話。サーモスタットも、白色センサーも、青色センサーも、ネットワーク構造は同じなので、同じクオリアを持つと言える、という話。
(吉田コメント) ここは私としては全く同意で、これがまさに盲視の話で繰り返し言及してきた「なにかあるかんじ」なのだと提唱したい。ただし、この“minimally conscious” photodiodeは空間は持っていないので、意識は構造化されていないわけで、「なにかあるかんじ」よりももっと原始的なものと言うのが正確だが。
(吉田コメント) あともうひとつ、ここでthe no-strong-loops hypothesisとの関連をコメントしておきたい。サーモスタットはrecurrentな結合を持っていて、それがのnon-zeroのφを作っている。それはいいのだけれども、実際にこのような1対1対応の強いrecurrentの結合が脳にあるかというとそれは疑わしい。実際問題としてこういうstrong loopはfeedbackによって強い持続的な発火を起こしてしまい、安定したネットワークとして活動できないだろう。このような「強いループ」が皮質-視床ネットワークには存在しないだろうと予言したのがCrick and Kochの"the no-strong-loops hypothesis"論文。
(吉田コメント) これはあくまでproposalでしかないが、cortico-corticalでの結合でこのようなstrong loopが無いということはJohnson and Burkhalter 2004 JNSによる解剖学的研究からすでに示されている。このようにして、strong-loopではφが大きくなるが、しかしそのようなネットワークでの意識レベルが高いとはいえそうにないので実際の意識経験と整合的でない。これはIITがうまい説明を考えないといけない課題のひとつだといえるだろう。
4-3. 哲学的ゾンビの可能性
IIT3.0論文のFig.20,21の話。同じ機能を果たすネットワークでも、完全にフィードフォワードなネットワーク(Φ=0)とフィードバックループのあるネットワーク(Φ>0)を作ることが可能である、という話。
(吉田コメント) これも盲視と繋げられると思っていて、上丘も大脳皮質もサリエンシー検出という同じ機能を果たすことができるのだけれども、上丘は主にフィードフォワードなネットワークでできていて、大脳皮質はフィードバックを使っていて、これが意識経験の有る無しに関わっていると議論できる。
次回へつづく。
- / ツイートする
- / 投稿日: 2016年11月28日
- / カテゴリー: [トノーニの意識の統合情報理論]
- / Edit(管理者用)